
Spis treści:

Dowiedz się: Algorytmy i struktury danych dla programistów
Dowiedz się więcej
Inżynier oprogramowania specjalizująca się w rozwoju systemów zarządzania infrastrukturą miejską dla megamiast na całym świecie. Główne obszary jej pracy obejmują programowanie po stronie serwera i projektowanie baz danych. Aktywnie dzieli się swoimi doświadczeniami i nowymi pomysłami na Twitterze pod nazwą @ValeriiZhyla.
Linki odgrywają kluczową rolę w treściach internetowych, zapewniając nawigację i dostęp do dodatkowych informacji. Pomagają użytkownikom poruszać się po witrynie i znajdować potrzebne zasoby. Efektywne wykorzystanie linków poprawia komfort użytkowania i przyczynia się do optymalizacji witryny pod kątem wyszukiwarek. Ważne jest, aby uwzględnić zarówno linki wewnętrzne, jak i zewnętrzne. Linki wewnętrzne łączą strony witryny, co pomaga wyszukiwarkom indeksować treści. Linki zewnętrzne kierujące do wiarygodnych źródeł zwiększają zaufanie do witryny. Optymalizacja tekstu kotwicy jest również ważna: powinien być informacyjny i trafny. Umieszczanie linków w treści pomaga zwiększyć jej wartość i poprawia widoczność w wyszukiwarkach. Prawidłowe rozmieszczenie linków i ich liczba mogą znacząco wpłynąć na pozycję witryny w wynikach wyszukiwania.
W tym artykule omówimy algorytmy sortowania: sortowanie bąbelkowe, sortowanie przez wstawianie i sortowanie przez wybieranie. Dowiesz się, jak działa każdy z tych algorytmów, a także o ich zaletach i wadach. Przeprowadzimy każdy algorytm krok po kroku, omawiając podstawowe implementacje i sugerując potencjalne ulepszenia. Algorytmy te stanowią podstawę do zrozumienia bardziej złożonych metod sortowania i pomogą Ci lepiej zrozumieć efektywność algorytmów.
W tym tekście zakładamy, że znasz takie pojęcia jak „najgorsza złożoność czasowa algorytmu wynosi O(n^2)”. Od tego momentu będę używać skrótów „złożoność czasowa” i „złożoność przestrzenna”. Zrozumienie tych pojęć jest ważnym aspektem algorytmów i analizy ich wydajności.
Jeśli dopiero zaczynasz zgłębiać teorię algorytmów, zalecamy najpierw przeczytanie artykułu Valery'ego na temat notacji Big O. Zawiera on jasne wyjaśnienie złożoności algorytmicznej i sposobu jej prawidłowego obliczania. Zrozumienie notacji Big O to ważny krok w opanowaniu algorytmów i doskonaleniu umiejętności programowania.
Na jakie pytania należy odpowiedzieć przed sortowaniem tablicy?Przygotowując się do sortowania elementów tablicy, programista powinien rozważyć kilka kluczowych pytań. Po pierwsze, jaki algorytm sortowania zostanie użyty? Istnieje wiele algorytmów, takich jak sortowanie szybkie, sortowanie przez scalanie czy sortowanie bąbelkowe, a wybór odpowiedniego zależy od charakterystyki problemu i ilości danych. Po drugie, jaki typ danych zawiera tablica? Sortowanie liczb, ciągów znaków lub obiektów może wymagać różnych podejść. Ważne jest również określenie, czy sortowanie powinno być wykonywane w kolejności rosnącej, czy malejącej. Inną ważną kwestią jest wydajność algorytmu: jak szybko może on przetwarzać tablicę wraz ze wzrostem jej rozmiaru? Na koniec warto rozważyć potrzebę zachowania oryginalnej tablicy: czy konieczne jest utworzenie nowej tablicy z posortowanymi elementami, czy wystarczy zmodyfikować istniejącą? Odpowiedzi na te pytania pomogą programiście wybrać optymalne podejście do sortowania tablicy.
Sortowanie oryginalne to metoda, w której oryginalna tablica danych jest modyfikowana podczas procesu sortowania. Główną wadą tego podejścia jest utrata stanu oryginalnej tablicy, co w niektórych przypadkach może mieć krytyczne znaczenie. Wartość oryginalnej tablicy zależy od konkretnego zadania i kontekstu użycia. Należy zauważyć, że to podejście może prowadzić do niepożądanych efektów ubocznych, co czyni je mniej preferowanym w sytuacjach, w których konieczne jest zachowanie oryginalnych danych.
Stosowanie podejścia bez tworzenia kopii tablicy pozwala na znaczną optymalizację zużycia pamięci. W tym przypadku złożoność pamięci pozostaje na poziomie O(1), co jest efektywnym rozwiązaniem. Co więcej, brak konieczności kopiowania tablicy prowadzi do oszczędności czasu, zmniejszając złożoność czasową o O(n). Dzięki temu algorytm jest bardziej wydajny i ekonomiczny.
Sortowanie kopiujące (out-of-place) to metoda, w której oryginalna tablica nie jest modyfikowana. W tym przypadku nie występują żadne skutki uboczne, ale złożoność algorytmu, zarówno czasowa, jak i pamięciowa, wzrasta do O(n). Warto zauważyć, że dodatkowy czas O(n) poświęcony na kopiowanie nie jest tak krytyczny w porównaniu z czasem potrzebnym na samo sortowanie, które może być znacznie dłuższe. Jednak dodatkowa pamięć O(n) stanowi poważne ograniczenie w przypadku stosowania algorytmów out-of-place, szczególnie przy ograniczonych zasobach.

Napiszmy funkcję, która efektywnie zamienia dwa elementy na podstawie ich indeksów:
Funkcja swap() przyjmuje tablicę i dwa indeksy. Najpierw zapisuje wartość elementu o indeksie first_idx w zmiennej temp. Następnie wartość elementu o indeksie snd_idx jest przypisywana do elementu o indeksie first_idx. W tym momencie zawartość obu elementów staje się identyczna, a oryginalna wartość z first_idx jest zapisywana w zmiennej temp. Na koniec przypisujemy tę wartość do elementu o indeksie snd_idx. W ten sposób funkcja swap() efektywnie zamienia wartości dwóch elementów w tablicy.
Wymienione powyżej identyfikatory są szeroko stosowane w programowaniu. Wartości tymczasowe są zazwyczaj przechowywane w zmiennej temp, która jest skrótem od słowa „temporary” (tymczasowy). Skróty fst i snd oznaczają odpowiednio „first” (pierwszy) i „second” (drugi). Słowo „index” jest często zapisywane jako idx, ponieważ programiści mają tendencję do oszczędnego używania liter.
Zacznijmy od tego, że porównywanie elementów tablicy to ważny krok w sortowaniu danych. Ale co zrobić po ich porównaniu? Zgadza się, zamienić elementy. Ten proces może znacznie poprawić kolejność w tablicy i zmniejszyć bałagan. Prawidłowe sortowanie danych jest kluczem do efektywnej pracy z tablicami i szybkiego dostępu do potrzebnych informacji. Porównywanie i zamiana elementów pomoże Ci osiągnąć pożądany rezultat i zoptymalizować strukturę danych.
Niniejszy artykuł powstał na podstawie dyskusji Valery'ego na Twitterze. Wątek ten omawia ważne aspekty związane z aktualnymi trendami i problemami w danym obszarze. Koncentruje się na kluczowych kwestiach społecznych, a także na możliwych rozwiązaniach. Valery dzieli się swoimi przemyśleniami i analizami, pozwalając czytelnikom lepiej zrozumieć sytuację. Dyskusja na Twitterze staje się platformą wymiany opinii i kształtowania opinii publicznej. Niniejszy artykuł uzupełnia wątek, zapewniając bardziej szczegółowy przegląd i analizę poruszanych tematów.
Porównywanie elementów tablicy z sąsiednimi indeksami to główny krok sortowania. Jeśli wartość elementu o indeksie i jest większa niż wartość elementu o indeksie i + 1, należy je zamienić miejscami. To podejście pozwala na stopniowe sortowanie tablicy. Rozważmy implementację tego algorytmu w kodzie.
«`python
for i in range(len(array) — 1):
if array[i] > array[i + 1]:
array[i], array[i + 1] = array[i + 1], array[i]
«`
Ten kod sekwencyjnie porównuje elementy tablicy i w razie potrzeby zamienia je miejscami. Tę metodę można wykorzystać w bardziej złożonych algorytmach sortowania, takich jak sortowanie bąbelkowe.
Ten kod stanowi doskonałą podstawę do implementacji sortowania tablicy od najmniejszego do największego elementu. Należy go jednak ulepszyć, aby osiągnąć optymalną wydajność i efektywność.
Najpierw stosujemy określone polecenia do wszystkich elementów tablicy z wyjątkiem ostatniego. Jest to konieczne, aby uniknąć sytuacji, w której tablica przekroczy zakres i w rezultacie wystąpi błąd. Dlatego używamy n — 1.
Ten kod nie ma na celu sortowania tablicy, ale pomoże uporządkować jej elementy. Oto przykład, jak to działa:

Uwaga: prawie wszystkie elementy Tablica przesunęła się we właściwym kierunku, a największy element (9) znalazł się w komórce najbardziej na prawo. Przy każdej iteracji zamieniał się miejscami z sąsiadem po prawej, powodując „wypływanie na powierzchnię”. Ten proces ilustruje zasadę sortowania, w której największy element stopniowo przesuwa się do swojego ostatniego miejsca w posortowanej tablicy.
Uruchommy nasz kod jeszcze kilka razy.
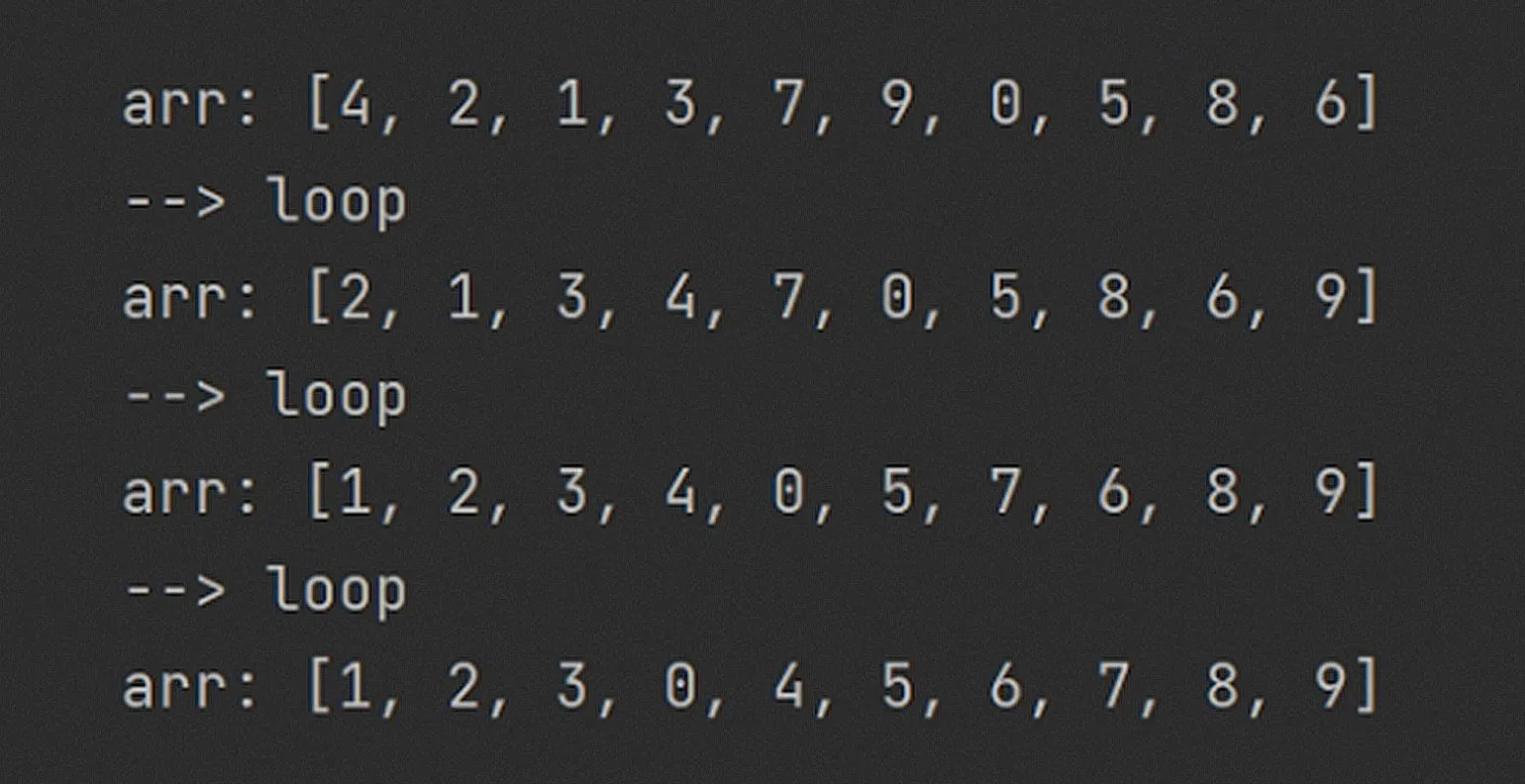
Po trzech przejściach dane stały się znacznie bardziej uporządkowane. Każda runda algorytmu zapewnia prawidłowe rozmieszczenie jednego z elementów: w pierwszym kroku na miejsce zajęła liczba 9, w drugim – liczba 8, a następnie, dzięki szczęśliwemu zbiegowi okoliczności, cztery elementy zostały poprawnie umieszczone naraz. Takie podejście pozwala nam efektywnie uporządkować dane i zoptymalizować proces sortowania.
Aby zagwarantować posortowanie tablicy, konieczne jest wykonanie określonej liczby permutacji. Biorąc pod uwagę, że w każdym przejściu algorytm przesuwa co najmniej jeden element na jego pozycję końcową, pełne posortowanie tablicy będzie wymagało co najmniej n przejść. Jednak n — 1 przejść jest wystarczające, ponieważ w ostatnim przejściu będzie tylko jedna opcja rozmieszczenia dla elementu najbardziej na prawo. Dzięki temu algorytm sortowania jest wydajny, zwłaszcza gdy liczba elementów w tablicy jest duża.
Prezentujemy pierwszy algorytm sortowania – sortowanie bąbelkowe. Metoda ta działa poprzez przenoszenie większych elementów na górę, a mniejszych na dół w każdej iteracji. Nazwa algorytmu inspirowana jest analogią do pęcherzyków powietrza unoszących się w wodzie. Sortowanie bąbelkowe to prosty, a zarazem intuicyjny sposób porządkowania danych, co czyni go popularną metodą nauczania podstaw algorytmów i struktur danych.
Jak działa sortowanie bąbelkowe
Nasza implementacja algorytmu sortowania bąbelkowego jest prosta: jego złożoność czasowa w najlepszym i najgorszym przypadku wynosi O(n^2). Chociaż to podejście jest dość niezawodne, istnieją bardziej wydajne algorytmy sortowania, które mogą znacznie poprawić wydajność. Możemy rozważyć alternatywne metody, takie jak sortowanie przez scalanie lub sortowanie szybkie, które oferują niższą złożoność czasową i zoptymalizowane wykorzystanie zasobów.
Każde wykonanie pętli wewnętrznej skutecznie przesuwa jeden element z prawej strony do jego właściwej pozycji. Dzięki temu każda nowa wartość j zmniejsza zakres pętli wewnętrznej o jeden. Dzięki temu nie ma potrzeby przetwarzania elementów, które już znajdują się na swoich miejscach. Optymalizuje to proces sortowania i zwiększa jego wydajność.
W wierszu 3 należy dodać przesunięcie j. Pozwoli to na prawidłowe dostosowanie pozycjonowania elementów i poprawi czytelność kodu. Należy pamiętać, że poprawnie określone przesunięcie pomaga zoptymalizować program i zwiększyć jego wydajność. Upewnij się, że wprowadzone zmiany odpowiadają ogólnej logice algorytmu i nie powodują błędów w dalszych obliczeniach.
Program został ulepszony, ale nadal wykonuje wiele niepotrzebnych operacji. Kilka elementów może „wyskoczyć” jednocześnie w jednej iteracji. Jak możemy zagwarantować, że program zatrzyma się po całkowitym posortowaniu tablicy? Można to zrobić w następujący sposób:
Pierwszym krokiem jest dodanie sprawdzenia, czy podczas iteracji wykonano co najmniej jedną permutację. Jeśli nie wystąpiły żadne permutacje, tablica jest sortowana, a program może się zakończyć. To znacznie zmniejszy liczbę iteracji i poprawi wydajność algorytmu sortowania.
Można również użyć flagi, która wskaże potrzebę kontynuowania sortowania. Jeśli w bieżącej iteracji nie nastąpią żadne zmiany, program zostanie zakończony. W ten sposób można zoptymalizować proces sortowania i poprawić wydajność programu.
W naszym opracowaniu dodano nową zmienną, która jest inicjowana na wartość false na początku pętli zewnętrznej. Po każdej wymianie (swap) zmienna ta zmienia swoją wartość na true. Pozwala to na efektywne śledzenie zmian podczas wykonywania algorytmu. Użycie tej zmiennej pomaga zoptymalizować kod i poprawić jego wydajność.
Jeśli pętla wewnętrzna nie wykona ani jednej wymiany (swap), zmienna pozostanie false, co doprowadzi do zakończenia pętli zewnętrznej. Zatem w najlepszym przypadku złożoność czasowa algorytmu wynosi O(n).
Jeśli algorytm działa z już posortowaną tablicą, jedno przejście pętli wewnętrznej wystarczy, aby wykryć brak permutacji, co pozwala na zakończenie pętli zewnętrznej. To rozwiązanie przypomina metodę sortowania bąbelkowego, którą można bezpiecznie zaprezentować na rozmowie kwalifikacyjnej.
Owińmy kod funkcją i kontynuujmy rozwijanie naszego pomysłu. Pozwoli nam to ustrukturyzować kod, zwiększając jego czytelność i możliwość ponownego użycia. Funkcje upraszczają proces programowania, ponieważ zapewniają modułowość i łatwość debugowania. Skupmy się na tworzeniu wydajnego i zrozumiałego kodu, który będzie łatwy do zaadaptowania do nowych problemów.
Tabela przedstawia wartości złożoności czasowej dla różnych scenariuszy: najlepszych, średnich i najgorszych przypadków danych wejściowych, a także wartości złożoności przestrzennej (złożoności przestrzennej). Te metryki są kluczowe dla oceny skuteczności algorytmów i pomagają programistom wybierać optymalne rozwiązania do przetwarzania danych. Właściwe zrozumienie złożoności czasowej i przestrzennej pozwala poprawić wydajność aplikacji i zoptymalizować wykorzystanie zasobów.
Jak działa sortowanie przez wybór
Sortowanie bąbelkowe opiera się na porównywaniu sąsiednich elementów tablicy. Istnieją jednak inne metody sortowania tablic. Rozważmy kilka alternatywnych podejść. Na przykład sortowanie szybkie (quicksort), które dzieli tablicę na podtablice i sortuje je rekurencyjnie. Inną popularną metodą jest sortowanie przez scalanie (merge sort), w którym tablica jest dzielona na dwie połowy, z których każda jest sortowana oddzielnie, a następnie łączona w posortowaną tablicę. Istnieją również inne algorytmy, takie jak sortowanie przez wstawianie i sortowanie przez wybór, z których każdy ma swoje zalety i wady. Wybór metody sortowania zależy od konkretnych warunków, takich jak rozmiar tablicy i jej stan przed sortowaniem.
Karty z liczbami są rozrzucone na stole przed chłopcem (lub dziewczynką). Zadaniem jest ułożenie tych liczb w kolejności rosnącej. Najpierw znajdują kartę z najmniejszą liczbą i kładą ją na sąsiednim stole. Następnie wracają do potasowanych kart i znajdują kolejną najmniejszą liczbę. Po zabraniu tej karty kładą ją na drugim stole, znajdującym się na prawo od pierwszej. Ta metoda pozwala nam efektywnie uporządkować liczby w kolejności rosnącej.
Chłopiec utworzy sekwencję liczb krok po kroku. Łatwo zgadnąć, że ta tablica będzie posortowana rosnąco: najmniejsza liczba będzie po lewej stronie, a największa po prawej. Tak działa naiwne sortowanie przez wybór, znane jako sortowanie przez wybór. Rozważmy, jak ten algorytm można zaimplementować w kodzie.
Aby efektywnie znaleźć indeks najmniejszego elementu w tablicy, możemy użyć wyspecjalizowanej funkcji. Funkcja ta iteruje po elementach tablicy, określa, który z nich ma najmniejszą wartość i zwraca odpowiedni indeks. Takie podejście pozwala na optymalne przetwarzanie danych i upraszcza dalszą manipulację tablicą. Należy pamiętać, że podczas implementacji tej funkcji należy uwzględnić możliwe błędy, takie jak puste tablice. Prawidłowe postępowanie w takich przypadkach zapewni stabilność algorytmu i jego poprawność w różnych scenariuszach.
Zmienna current_min_value mogłaby zostać pominięta, ale wolę ją pozostawić dla lepszego zrozumienia kodu. Ta zmienna pomaga nam wizualnie śledzić wartość minimalną, co może być przydatne do dalszej analizy danych lub debugowania.
Funkcja find_min() ma prosty cel: znajduje wartość minimalną w tablicy. Zaczynamy od ustawienia bieżącego minimum jako pierwszego elementu tablicy. Następnie sekwencyjnie porównujemy ten element z pozostałymi. Jeśli napotkamy wartość mniejszą od bieżącego minimum, aktualizujemy zmienną current_min_value. W ten sposób funkcja pozwala nam efektywnie określić najmniejszy element tablicy za pomocą prostego algorytmu porównania.
Zakładamy, że tablica arr zawiera co najmniej jeden element i że wszystkie jej komórki są wypełnione wartościami liczbowymi. W przeciwnym razie funkcja find_min() może być jeszcze bardziej złożona i trudna do zrozumienia.
Aby zaimplementować funkcję usuwającą element z tablicy, możemy zastosować proste podejście. Funkcja ta przyjmuje dwa parametry: oryginalną tablicę i element do usunięcia. Funkcja zwróci nową tablicę, z której określony element zostanie wykluczony. Ta metoda pozwala nam zachować oryginalną tablicę i poprawia czytelność kodu. Przykładowa implementacja może wyglądać następująco:
«`javascript
function removeElement(arr, element) {
return arr.filter(item => item !== element);
}
«`
Ta funkcja używa metody `filter`, która tworzy nową tablicę zawierającą tylko te elementy, które nie są równe przekazanej wartości. Daje nam to przejrzysty i zrozumiały kod, który skutecznie usuwa element z tablicy.
Przygotowania są zakończone i teraz możemy rozpocząć sortowanie. Stopniowo zmniejszymy oryginalną tablicę, tworząc wynik w nowej tablicy. Na początek utworzymy pustą tablicę o takim samym rozmiarze jak oryginalna.
W następnym kroku zaimplementujemy kroki naszego eksperymentu myślowego w postaci kodu programu. Pozwoli nam to wyraźnie zobaczyć, jak teoretyczne koncepcje można zastosować w praktyce. Kod programu będzie odzwierciedlał główne zasady, które omówiliśmy, i demonstrował ich funkcjonalność. W ten sposób będziemy mogli analizować wyniki i wyciągać wnioski na podstawie uzyskanych danych. Podejście do pisania kodu będzie systematyczne i spójne, co zapewni jego zrozumiałość i łatwość użycia w przyszłości.
Dotyczące algorytmu mogą pojawić się następujące uwagi:
1. Wydajność: Algorytm może wykazywać słabą wydajność podczas przetwarzania dużych ilości danych, co może negatywnie wpłynąć na szybkość wykonywania zadania.
2. Złożoność: Złożoność algorytmu może utrudniać jego zrozumienie i wdrożenie, szczególnie dla użytkowników o ograniczonej wiedzy w tym obszarze.
3. Elastyczność: Algorytm może nie uwzględniać wszystkich możliwych scenariuszy lub przypadków użycia, co ogranicza jego przydatność w różnych warunkach.
4. Skalowalność: Wraz ze wzrostem obciążenia algorytm może nie dostosowywać się do nowych warunków, co czyni go mniej niezawodnym w dłuższej perspektywie.
5. Dokładność: Możliwe są błędy obliczeniowe lub nieprawidłowe wyniki, co może prowadzić do błędnych wniosków i decyzji.
Te uwagi wymagają starannej analizy i rewizji algorytmu w celu poprawy jego wydajności i niezawodności.
- Zużywa zbyt dużo pamięci. Tworzymy osobną tablicę dla wyniku i otrzymujemy pamięć O(n).
- W oryginalnej tablicy pojawiają się luki. Funkcja delete_element() tworzy puste komórki w arr, na które funkcja find_min() się potknie.
- Wysoka złożoność czasowa. Algorytm wyraźnie nie wyróżnia się szybkością wykonania – O(n^2) zarówno w najgorszym, jak i najlepszym przypadku.
Pojawia się naturalne pytanie: co zrobić w tej sytuacji? Na początku może się to wydawać mylące, ale zapewniam, że wkrótce wszystko stanie się jasne i logiczne.
Oto zoptymalizowany kod algorytmu sortowania przez wybór. Algorytm ten sortuje elementy bezpośrednio w oryginalnej tablicy arr, bez tworzenia dodatkowej tablicy. Sortowanie przez wybór to prosty, ale efektywny sposób porządkowania danych w małych kolekcjach. Jego główną zaletą jest to, że działa z minimalnym wykorzystaniem pamięci, ponieważ nie wymaga dodatkowych struktur do przechowywania posortowanych danych.
«`python
def selection_sort(arr):
n = len(arr)
for i in range(n):
min_idx = i
for j in range(i + 1, n):
if arr[j] < arr[min_idx]:
min_idx = j
arr[i], arr[min_idx] = arr[min_idx], arr[i]
return arr
«`
Ten kod implementuje sortowanie przez wybór poprzez znalezienie minimalnego elementu w nieposortowanej części tablicy i przeniesienie go na jej początek. Pozwala to na efektywne sortowanie tablicy przy minimalnym zużyciu pamięci, dzięki czemu algorytm nadaje się do pracy z małymi ilościami danych.
Opracowałem funkcję find_min_between(array, start_idx, end_idx), która wykonuje to samo zadanie co find_min(array), ale jest ograniczona do pewnego zakresu indeksów od start_idx do end_idx. Pozwala to na efektywniejsze znalezienie minimalnej wartości w danej sekcji tablicy. Funkcja swap(array, i, j) również pozostaje niezmieniona i nie wymaga dalszych wyjaśnień.
Przyjrzyjmy się teraz, jak działa ulepszona wersja sortowania przez wybór. Zacznijmy od tablicy arr zawierającej dziesięć liczb. Ulepszone sortowanie przez wybór optymalizuje proces, zmniejszając liczbę zamian elementów i poprawiając ogólną wydajność sortowania. Zamiast wykonywać zamiany na każdym kroku, algorytm najpierw znajduje najmniejszy element w pozostałej tablicy, a następnie wykonuje pojedynczą zamianę, aby przenieść ten element na właściwą pozycję. Zmniejsza to liczbę operacji, szczególnie podczas pracy z dużymi tablicami. Zaawansowane sortowanie przez wybór może znacząco poprawić wydajność w porównaniu z metodą klasyczną, zwłaszcza w zadaniach, w których ważna jest szybkość przetwarzania danych.

W tym przykładzie przejdziemy przez tablicę kilka razy, używając algorytmu sortowania przez wybieranie, i przeanalizujemy stan tablicy arr na każdym kroku. Wyniki działania algorytmu pozwolą nam zobaczyć, jak przebiega sortowanie i jak zmienia się kolejność elementów w tablicy.

Algorytm utrzymuje kolejność elementów po lewej stronie tablicy arr, wykorzystując barierę oddzielającą część posortowaną od nieposortowanej. Bariera ta znajduje się między elementami o indeksach i oraz (i + 1). Takie podejście zapewnia efektywną dystrybucję danych i utrzymuje ich kolejność, co pomaga zoptymalizować sortowanie i poprawić wydajność algorytmu.
W każdej iteracji algorytm znajduje minimalną wartość po prawej stronie tablicy, zaczynając od indeksu i + 1 i kontynuując do końca, i zamienia tę wartość z elementem o indeksie i. Zatem dla i = 1 posortowana część tablicy zawiera tylko jeden element, natomiast dla i = 2 są to dwa elementy. Takie podejście zapewnia spójne uporządkowanie elementów tablicy, co sprawia, że algorytm jest wydajny w sortowaniu danych.
Proces sortowania można uprościć wizualnie, dodając wizualny separator między elementami tablicy po jednej stronie posortowanej części a nieposortowaną po drugiej. Takie podejście pomoże lepiej zrozumieć, jak przebiega proces sortowania, które elementy są już posortowane, a które nadal wymagają przetworzenia. Dzięki tej wizualnej reprezentacji łatwiej będzie śledzić proces i szybko zrozumieć algorytmy sortowania.
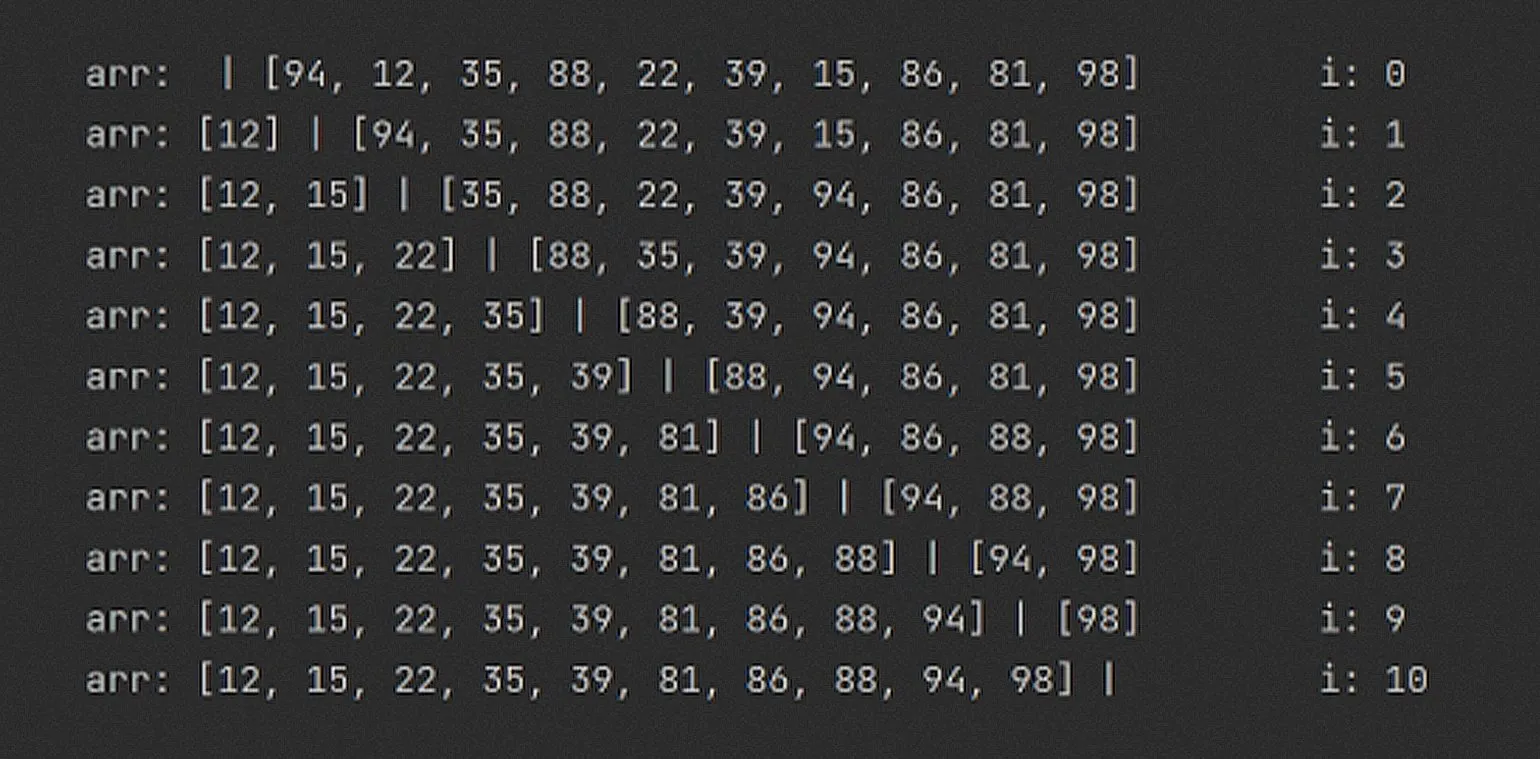
Pamiętaj, że stan tablicy arr jest wyświetlany na końcu każdej iteracji. Pierwszy wiersz odpowiada i = 0, drugi wiersz odpowiada i = 1 itd.
Idea algorytmu sortowania przez wybór jest teraz jasna i logiczna. Rozważmy jego główne cechy. Algorytm sortowania przez wybór sekwencyjnie znajduje minimalny element w nieposortowanej części tablicy i przenosi go na początek. Pozwala to na wydajne sortowanie danych. Sortowanie przez wybór ma złożoność czasową O(n²), co czyni je mniej wydajnym w przypadku dużych tablic. Jednak jego prostota i przejrzystość sprawiają, że jest dobrym wyborem do celów edukacyjnych i małych ilości danych. Omówmy teraz jego funkcje i zastosowania bardziej szczegółowo.
Ta implementacja ma zalety pod względem wykorzystania pamięci, osiągając złożoność O(1) dzięki pracy z lewą stroną tablicy. Jednak znalezienie minimalnego elementu wymaga czasu O(n) i jest wykonywane w każdej pętli, co daje całkowity czas wykonania O(n^2) zarówno w najgorszym, jak i najlepszym przypadku. To sprawia, że ta implementacja jest nieefektywna w przypadku dużych tablic, ponieważ czas wykonania znacznie wzrasta. Optymalizacja algorytmu może znacząco poprawić jego wydajność i uczynić go bardziej odpowiednim do pracy z dużymi wolumenami danych.
Na pierwszy rzut oka może się wydawać, że sortowanie bąbelkowe jest szybsze niż sortowanie przez wybór, dzięki lepszej złożoności czasowej, wynoszącej w najlepszym razie O(n). Jednak, jak to się mówi, istnieją pewne niuanse. W tym artykule rozważymy również aspekty nieobjęte notacją O i omówimy, dlaczego ważne jest, aby brać pod uwagę nie tylko teoretyczną złożoność, ale także praktyczny czas wykonania tych algorytmów w różnych sytuacjach.
Zaktualizujemy tabelę specyfikacji o nowe dane i wyjaśnienia. Pomoże to lepiej zrozumieć funkcje produktu i zwiększyć jego atrakcyjność dla potencjalnych nabywców. Zaktualizowana tabela będzie zawierała aktualne informacje o cechach, co poprawi optymalizację SEO i zwiększy widoczność strony w wyszukiwarkach.
Jak działa sortowanie przez wstawianie
Sortowanie przez wstawianie, znane również jako sortowanie przez wstawianie, ma wiele wspólnego z sortowaniem przez wybór. W rzeczywistości można je nazwać „odwrotnym sortowaniem przez wybór”, ponieważ wykorzystuje odwrotne podejście do organizacji danych. W przeciwieństwie do sortowania przez wybór, które znajduje najmniejszy element i umieszcza go na początku, sortowanie przez wstawianie stopniowo buduje posortowaną tablicę, wstawiając elementy jeden po drugim. Ten algorytm jest skuteczny w przypadku małych zestawów danych i może osiągać dobre wyniki w przypadku częściowo posortowanych kolekcji. Sortowanie przez wstawianie to prosta i intuicyjna metoda, dzięki czemu jest popularnym wyborem do nauki podstaw algorytmów sortowania.
W sortowaniu przez wybór znajdujemy najmniejszy element po prawej stronie tablicy i przenosimy go na koniec lewej strony. Proces ten jest kontynuowany, aż cała tablica zostanie posortowana. Najkosztowniejszą operacją w tym algorytmie jest znalezienie najmniejszego elementu, co może mieć wpływ na ogólną wydajność. Wydajność sortowania przez wybór maleje podczas pracy z dużymi ilościami danych ze względu na złożoność czasową O(n^2), co czyni je mniej preferowanym w porównaniu z innymi algorytmami sortowania, takimi jak sortowanie szybkie czy sortowanie przez scalanie. Sortowanie przez wybór jest jednak łatwe w implementacji i może być przydatne w przypadku małych tablic lub w celach edukacyjnych, aby zrozumieć podstawy sortowania.
Sortowanie przez wstawianie zachowuje uporządkowane elementy w oryginalnej tablicy. W tym algorytmie bierzemy pierwszy element z nieuporządkowanej prawej strony i wstawiamy go na odpowiednią pozycję w uporządkowanej lewej stronie. Ten proces jest powtarzany, aż cała tablica zostanie posortowana. Algorytm jest wydajny w przypadku małych ilości danych i działa ze złożonością czasową O(n^2) w najgorszym przypadku.
Lewa strona tablicy zawsze pozostaje posortowana. Oznacza to, że aby dodać nowy element, musimy tylko znaleźć odpowiednią pozycję wstawienia. Następnie przesuwamy wszystkie elementy po prawej stronie o jedną pozycję w prawo i wstawiamy nowy element w zwolnione miejsce. Takie podejście zapewnia sprawną aktualizację tablicy bez konieczności całkowitej reorganizacji jej struktury.
Algorytm sortowania przez wstawianie można porównać do zauroczenia w komunikacji miejskiej. Kiedy bokser wagi ciężkiej wchodzi do zatłoczonego tramwaju, jego pojawienie się powoduje, że wszyscy pasażerowie się poruszają, odsuwając ich o pół kroku od wyjścia. W algorytmie sortowania przez wstawianie elementy tablicy są porównywane i przesuwane jeden po drugim, aby przywrócić porządek. Ta metoda działa skutecznie na małych ilościach danych i demonstruje swoją skuteczność w przypadku tablic częściowo posortowanych, co czyni ją przydatną w pewnych sytuacjach.
Rozważmy przykład wstawiania liczby do posortowanej tablicy. Mamy posortowaną tablicę ośmiu liczb z pustą komórką na końcu. Zadaniem jest wstawienie liczby 5 na odpowiednią pozycję, zachowując kolejność sortowania. Algorytm wstawiania będzie wyglądał następująco: najpierw musimy iterować po elementach tablicy, porównując je z liczbą 5. Po znalezieniu elementu większego niż 5, przesuwamy wszystkie kolejne elementy o jedną pozycję w prawo i wstawiamy 5 na znalezioną pozycję. W ten sposób tablica pozostanie posortowana.
Rozpocznijmy przesuwanie liczb większych niż 5 w prawo. To działanie może być przydatne do uproszczenia analizy danych, wizualizacji lub porządkowania informacji. Przesunięcie liczb na pozycje boczne pozwala na ich podświetlenie i łatwiejsze do odczytania. To podejście jest często stosowane w różnych kontekstach, w tym w przetwarzaniu tablic i struktur danych. Kontynuując, możemy zastanowić się, jak takie metody wpływają na efektywność pracy z informacjami i poprawiają użyteczność.

Gdy przesuniesz liczbę, jej kopia pojawi się po prawej stronie, a oryginał zostanie zastąpiony sąsiednią wartością po lewej stronie w następnym kroku.
Po wykonaniu wszystkich przesunięć tablica będzie wyglądać następująco:

Gdy pętla osiągnie wartość 4, zakończy wykonywanie i zastąpi „śmieci” numer 6 numerem 5.

Przyjrzyjmy się teraz algorytmowi sortowania przez wstawianie (Insertion Sort). Ta metoda jest prosta, ale skuteczna w sortowaniu małych tablic. Algorytm przeszukuje tablicę, stopniowo zwiększając posortowaną część. Każdy element jest wstawiany w odpowiednie miejsce wśród już posortowanych danych. Sortowanie przez wstawianie (Insertion Sort) dobrze sprawdza się w przypadku tablic prawie posortowanych i wykazuje dobrą wydajność w takich przypadkach. Główną zaletą tego algorytmu jest jego prostota i łatwość implementacji, dzięki czemu idealnie nadaje się do celów edukacyjnych i rozwiązywania małych problemów sortowania. W następnej sekcji przyjrzymy się implementacji kodu algorytmu sortowania przez wstawianie (Insertion Sort), aby zrozumieć jego działanie w praktyce.
Przypomnijmy sobie barierę zastosowaną w algorytmie sortowania przez wybór (Selection Sort). Ponieważ algorytm sortowania przez wstawianie ma podobne zasady działania, zastosujmy do niego podobną technikę. Sortowanie przez wstawianie, podobnie jak sortowanie przez wybieranie, jest przeznaczone do sortowania tablic, ale działa na innej zasadzie. Zamiast szukać najmniejszego elementu, algorytm ten sekwencyjnie przesuwa elementy i wstawia je w odpowiednie miejsca. Zastosowanie bariery pozwala zoptymalizować proces, co zwiększa wydajność sortowania. Użycie tego podejścia może poprawić wydajność sortowania przez wstawianie w niektórych scenariuszach, zwłaszcza podczas pracy z częściowo posortowanymi tablicami.
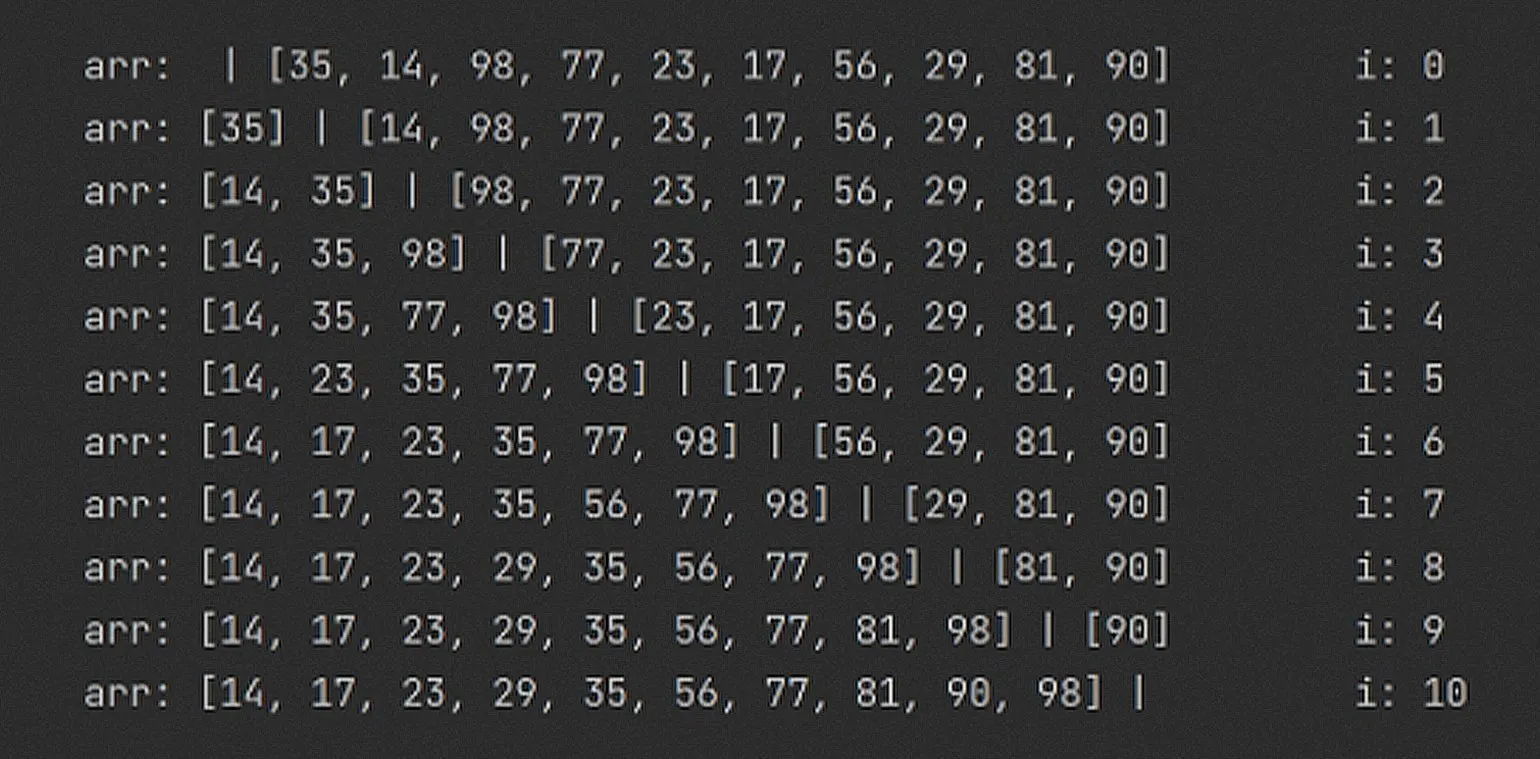
Dolna granica wydajności sortowania jest istotna. Jeśli tablica jest już posortowana, nie są wymagane żadne przesunięcia. W tym przypadku złożoność wynosi w najlepszym przypadku O(n), co sprawia, że sortowanie to jest szczególnie wydajne w przypadku posortowanych danych. Optymalizacja algorytmów sortowania może znacznie poprawić wydajność podczas pracy z dużymi tablicami, co ma praktyczne implikacje w różnych dziedzinach, w tym w przetwarzaniu danych i programowaniu algorytmicznym.
Omówiliśmy „Trzy Wielkie Sortowania”, z którymi spotyka się każdy, kto studiuje algorytmy. Gratulujemy podjęcia tego ważnego kroku w zrozumieniu podstaw sortowania algorytmicznego. Algorytmy te są kluczowymi narzędziami w programowaniu i przyczyniają się do optymalizacji pracy z danymi.
Czym jest stabilność sortowania?
Stabilny algorytm sortowania, znany również jako stabilny algorytm sortowania, zachowuje kolejność elementów o tych samych kluczach względem siebie. Oznacza to, że podczas sortowania obiektów o identycznych wartościach atrybutów ich pierwotna kolejność zostanie zachowana. Podczas sortowania liczb stabilność nie ma znaczenia, ale w przypadku obiektów, dla których istotna jest pierwotna kolejność, kluczowe stają się stabilne algorytmy sortowania. Stabilne algorytmy pomagają zapobiegać utracie informacji i zachować kontekst danych.
Aby posortować tablicę rekordów klientów według wieku, można użyć prostego formatu notacji, takiego jak [wiek : imię]. Takie podejście pozwala efektywnie uporządkować dane i szybko znaleźć potrzebne rekordy. Sortowanie według wieku pozwala uporządkować klientów, co może być przydatne w analizach i podejmowaniu decyzji biznesowych. Należy pamiętać, że prawidłowe sortowanie danych pomaga lepiej zrozumieć odbiorców i optymalizować interakcje z klientami. Korzystając z tego formatu, można łatwo przetwarzać i analizować informacje o wieku klientów, co z kolei poprawia jakość obsługi i zwiększa skuteczność strategii marketingowych.

Po wykonaniu stabilnego sortowania element Kuzya będzie znajdował się nad elementem Oleg. Dzieje się tak, ponieważ sortowanie stabilne zachowuje kolejność elementów o tych samych kluczach, co w oryginalnych danych. Dzięki temu podczas sortowania Kuzya będzie na pewno przed Olegiem.

W warunkach niestabilności, drugi scenariusz.

Stabilność jest kluczowa Czynnik przy sortowaniu tablic obiektów według wielu kryteriów. Na przykład, jeśli sortujemy dane najpierw według wieku, następnie według stanu konta bankowego, a na końcu według powierzchni domu, niestabilny algorytm może generować nieprzewidywalne wyniki. W takich przypadkach ważne jest stosowanie stabilnych algorytmów sortowania, aby zapewnić, że obiekty o identycznych wartościach dla pierwszego kryterium zachowają swoją pierwotną kolejność. Jest to szczególnie ważne w aplikacjach, w których dokładność i przewidywalność danych mają kluczowe znaczenie. Wybór stabilnego algorytmu sortowania pomoże uniknąć nieporozumień i zapewni dokładniejsze i bardziej logiczne wyniki.
W naszej grupie algorytmów sortowania dwie metody, sortowanie bąbelkowe i sortowanie przez wstawianie, charakteryzują się stabilną wydajnością, podczas gdy sortowanie przez wybieranie jest podatne na tasowanie elementów. Stabilne algorytmy sortowania zachowują kolejność równych wartości, co czyni je preferowanymi w przypadku niektórych zadań. Sortowanie bąbelkowe i sortowanie przez wstawianie zapewniają ten rodzaj stabilności, który może mieć kluczowe znaczenie w przetwarzaniu danych. Jednocześnie sortowanie przez wybór nie gwarantuje zachowania kolejności, co ogranicza jego zastosowanie w niektórych scenariuszach.
Dodajmy do naszej tabeli charakterystykę algorytmu sortowania przez wybór, w tym informacje o stabilności. Pozwoli nam to pełniej ocenić jego wydajność i przydatność w różnych scenariuszach.
Czego nie uwzględnia notacja O(n)
Obiecałem omówić aspekty, których nie uwzględnia notacja O. Teraz czas na analizę wad i cech popularnych algorytmów.
Rozważmy tablicę, która jest niemal idealnie posortowana. Prawie – bo największy element jest pierwszy.

Algorytmy wykorzystywane w różnych dziedzinach dostosuje się do Algorytmy są projektowane tak, aby sprostać zmieniającym się warunkom i wymaganiom. Są one w stanie analizować i przetwarzać duże ilości danych, biorąc pod uwagę liczne czynniki, takie jak zachowania użytkowników, trendy rynkowe i postęp technologiczny. Oczekuje się, że algorytmy staną się jeszcze bardziej wydajne w najbliższej przyszłości, poprawiając jakość świadczonych usług i zwiększając poziom personalizacji. Będą one uwzględniać nie tylko nawyki użytkowników, ale także ich preferencje, co przełoży się na bardziej intuicyjne interfejsy i rozwiązania. Ponadto ważnym trendem będzie nacisk na przejrzystość algorytmów, pomagając użytkownikom lepiej zrozumieć, jak podejmowane są decyzje i na jakich danych się opierają. W ten sposób algorytmy będą nie tylko narzędziem do analizy danych, ale także ważnym elementem interakcji z użytkownikiem, przyczyniając się do lepszego ogólnego doświadczenia użytkownika.
- Sortowanie bąbelkowe będzie działać znakomicie. Po n permutacjach największy element „przepłynie” na górę.
- Sortowanie przez wstawianie również sprawdza się w tym przypadku.
- Sortowanie przez wybieranie będzie bardzo nieefektywne i nieefektywne, przeszukując całą tablicę i osiągając czas O(n^2).
Jeśli dane są prawie posortowane, algorytmy sortowania, takie jak sortowanie bąbelkowe i sortowanie przez wstawianie, stają się najskuteczniejszymi narzędziami. Metody te dają doskonałe rezultaty w pracy z tablicami prawie posortowanymi, zapewniając szybkie sortowanie przy minimalnym nakładzie zasobów. Wybór między nimi zależy od konkretnych warunków i wymagań problemu, ale oba algorytmy mogą znacznie przyspieszyć przetwarzanie danych w takich przypadkach.
Rozważmy teraz koszt operacji. Chociaż ten aspekt nie jest omawiany w notacji O, ważne jest, aby zrozumieć, że różne operacje wymagają różnych zasobów komputera. Wydajność operacji może się znacznie różnić w zależności od złożoności algorytmu i ilości przetwarzanych danych. Zrozumienie tych niuansów pomaga programistom optymalizować kod i wybierać najefektywniejsze rozwiązania dla konkretnych zadań.
Odczyt wartości z komórki tablicy to proste zadanie. Nadpisanie komórki może wydawać się jednak proste, ale w praktyce pojawiają się komplikacje z powodu wielowątkowości, aktualizacji wartości w pamięci podręcznej procesora i innych czynników. W związku z tym operacja swap() okazuje się bardziej złożona, niż mogłoby się początkowo wydawać.
W tej sekcji przyjrzymy się liczbie wykonanych swapów. Jest to ważny wskaźnik, który pozwala nam ocenić aktywność platformy i poziom zainteresowania użytkowników różnymi zasobami. Analizując dane dotyczące swapów, możemy zidentyfikować trendy i preferencje, co pomoże nam w dalszej optymalizacji naszej oferty rynkowej. Upewnij się, że jesteś na bieżąco z najnowszymi zmianami i aktualizacjami w obszarze swapów, aby podejmować świadome decyzje.
- Sortowanie bąbelkowe to potwór, który nieustannie dokonuje swapów. Liczba operacji zapisu jest tutaj nie do przebicia.
- Sortowanie przez wstawianie również nie jest łatwe – ciągłe przesuwanie elementów w prawo nie przyniesie żadnych korzyści.
- Sortowanie przez wybór to perełka! Tylko n zamian w najgorszym przypadku. Bardzo wydajny algorytm.
Jeśli Twoim celem jest optymalizacja kosztów operacji zapisu, sortowanie przez wybór jest najodpowiedniejszą opcją. Ten algorytm jest wydajny pod względem redukcji liczby operacji zapisu, co czyni go idealnym do stosowania w środowiskach o ograniczonych zasobach lub gdy konieczne jest zminimalizowanie zużycia pamięci.
Wszystkie trzy algorytmy wykazują podobną wydajność pod względem wykorzystania pamięci. Działają w miejscu, co pozwala im na wykorzystanie pamięci O(1).
Algorytmy sortowania zawsze można ulepszyć, zwłaszcza przy użyciu wyspecjalizowanych struktur danych. Na przykład sortowanie przez wstawianie można zoptymalizować, podwajając jego szybkość i zmniejszając liczbę zamian do poziomu porównywalnego z sortowaniem bąbelkowym, używając listy powiązanej zamiast tablicy. Ponadto algorytm sortowania przez wybór można zmodyfikować tak, aby zachowywał się jak algorytm stabilny. Otwiera to nowe możliwości poprawy wydajności sortowania danych i rozszerza zakres zastosowania różnych algorytmów w zależności od konkretnych problemów.
Co czytać i oglądać
Na stronie geeksforgeeks.org można znaleźć kod sortujący zaimplementowany w różnych językach programowania, a także filmy demonstrujące wizualizacje tych algorytmów. Zasób oferuje szeroki wybór przykładów, które pozwalają lepiej zrozumieć zasady sortowania i ich zastosowanie w rzeczywistych problemach.
- Sortowanie bąbelkowe
- Sortowanie przez wybór
- Sortowanie przez wstawianie
Na YouTube znajduje się wiele wizualizacji algorytmów sortowania, ale chciałbym zwrócić uwagę na jeden film, który wyróżnia się spośród innych. Film ten szczegółowo demonstruje różne algorytmy sortowania, ich zasady działania i wydajność. To doskonałe źródło wiedzy dla osób, które chcą lepiej zrozumieć, w jaki sposób różne algorytmy wpływają na przetwarzanie danych. Porównywanie reprezentacji wizualnych pomaga lepiej zrozumieć materiał i wybrać optymalne podejście do rozwiązywania problemów sortowania.
Tańce węgierskie to wyjątkowe zjawisko kulturowe, łączące w sobie elementy tradycji i rozrywki. Są one nie tylko zabawne, ale także edukacyjne, pozwalając na głębsze zrozumienie kultury węgierskiej i jej muzycznych cech. Ich energiczne ruchy i kolorowe stroje przyciągają uwagę i tworzą atmosferę zabawy. Tańce węgierskie zyskały popularność nie tylko na Węgrzech, ale także za granicą, zdobywając serca ludzi na całym świecie.
W tym momencie zakończyliśmy naszą dyskusję na temat prostych zagadnień. Mam nadzieję, że informacje zostały przedstawione jasno i zrozumiale. W przyszłych artykułach na temat algorytmów sortowania omówię bardziej szczegółowo metody takie jak Sortowanie przez scalanie i Sortowanie szybkie, zagłębiając się w ich funkcje i zastosowania.
Czytanie jest ważnym aspektem rozwoju osobistego. Pomaga poszerzać horyzonty, wzbogacać słownictwo i rozwijać krytyczne myślenie. Regularne czytanie nie tylko wzbogaca wiedzę, ale także pomaga radzić sobie ze stresem, poprawiając ogólne samopoczucie. Wybieraj różnorodne gatunki i tematy, aby czytanie było bardziej angażujące i satysfakcjonujące. Poznaj nowych autorów i książki i nie zapomnij podzielić się swoimi doświadczeniami z innymi. Czytanie jest kluczem do nowych możliwości i głębszego zrozumienia otaczającego nas świata.
- Notacja Big O: Czym jest i jak ją obliczyć
- GNU Emacs: Jak edytor tekstu z lat 80. uczy programistów cenić wolne oprogramowanie
- Expecto Pythonum: 15 zaklęć w języku węża
Algorytmy i struktury danych dla programistów
Zdobędziesz podstawową wiedzę i nauczysz się rozwiązywać rzeczywiste problemy za pomocą algorytmów. Będziesz w stanie znaleźć pracę w dowolnej firmie i uczestniczyć w złożonych, wysoko płatnych projektach.
Dowiedz się więcej