
Spis treści:
- Czym jest głębokie uczenie?
- Struktura i zasady działania prostej sieci neuronowej
- Struktura i zasady działania wielowarstwowej sieci neuronowej
- Głębokie uczenie i sieci neuronowe: podstawowe koncepcje
- Metody szkolenia sieci neuronowych: podstawy
- Przegląd algorytmów głębokiego uczenia: co musisz wiedzieć
- Zastosowania głębokiego uczenia: od medycyny po rozrywkę
- Najważniejsze punkty do zapamiętania

Sztuczna inteligencja: 5 kluczowych idei filozoficznych
Dowiedz się więcejCzym jest głębokie uczenie?
Głębokie uczenie to zaawansowane podejście do sztucznej inteligencji, które umożliwia komputerom efektywne rozwiązywanie złożonych problemów. Znajduje zastosowanie w rozpoznawaniu twarzy, identyfikacji obiektów na obrazach i generowaniu tekstu. Ta potężna technologia jest aktywnie wdrażana w różnych dziedzinach, w tym w medycynie, gdzie jest wykorzystywana do diagnozowania chorób, oraz w finansach, gdzie pomaga w analizie danych i przewidywaniu trendów rynkowych. Dzięki możliwości przetwarzania i analizowania dużych ilości informacji, głębokie uczenie staje się niezbędnym narzędziem do opracowywania innowacyjnych rozwiązań we współczesnym świecie.
Główną zasadą głębokiego uczenia jest trenowanie modeli na dużych zbiorach danych. Na przykład, aby komputer mógł odróżnić jabłka od bananów, musi otrzymać dużą liczbę obrazów każdego owocu i skupić się na ich charakterystycznych cechach. To podejście pozwala modelom identyfikować wzorce i cechy, które mogą nie być oczywiste dla ludzi, co z kolei ułatwia dokładniejszą klasyfikację i rozpoznawanie obiektów. Głębokie uczenie jest aktywnie wykorzystywane w różnych dziedzinach, takich jak przetwarzanie obrazu, rozpoznawanie mowy i analiza tekstu, co czyni je ważnym narzędziem w nowoczesnej technologii.
Gdy sieć neuronowa napotyka nowy obraz, który nie znajduje się w zestawie treningowym, stosuje swoje algorytmy do analizy i interpretacji obrazu. Sieci neuronowe to złożone modele matematyczne, które naśladują funkcjonowanie ludzkiego mózgu. Potrafią rozpoznawać wzorce i wyodrębniać kluczowe cechy, co pozwala im wyciągać wnioski na podstawie wcześniej niewidzianych danych. Ta właściwość sieci neuronowych czyni je potężnym narzędziem w dziedzinie widzenia komputerowego i sztucznej inteligencji, zdolnym do adaptacji do nowych warunków i zadań.
Sieć neuronowa to złożona struktura składająca się z wielu połączonych ze sobą neuronów, które aktywnie wymieniają informacje. Sieć ta jest zdolna do zapamiętywania danych i podejmowania decyzji w oparciu o otrzymane informacje. Sieci neuronowe działają w oparciu o modele matematyczne, w tym teorię prawdopodobieństwa i rachunek różniczkowy. Technologie te są szeroko stosowane w dziedzinach od przetwarzania obrazu po analizę dużych zbiorów danych, demonstrując wydajność i moc nowoczesnych algorytmów uczenia maszynowego. Sieci neuronowe, pomimo złożonej architektury i szerokiego zakresu zastosowań, nie są zdolne do kreatywności. Jak zauważa ChatGPT, sieci neuronowe nie potrafią tworzyć żartów, ponieważ humor wymaga dogłębnego zrozumienia kontekstu kulturowego i społecznego. Zamiast tego sieci neuronowe opierają się na obliczeniach statystycznych i przetwarzaniu danych. To ograniczenie podważa ich zdolność do autentycznego wyrażania się w sposób twórczy, ponieważ nie potrafią interpretować i tworzyć znaczeń w oparciu o ludzkie doświadczenie i percepcję emocjonalną. Zatem, chociaż sieci neuronowe mogą generować tekst i obrazy, nie mogą zastąpić prawdziwej kreatywności opartej na intuicji i percepcji sensorycznej.
Analizując obraz, sieć neuronowa koncentruje się na kluczowych cechach, takich jak kształt, kolor, tekstura i inne parametry. Następnie porównuje te cechy ze znanymi danymi, aby sklasyfikować obiekt, na przykład jako jabłko lub banana. Proces rozpoznawania obejmuje trenowanie na dużej liczbie obrazów, co pozwala modelowi na poprawę dokładności decyzji.
Aby poprawić dokładność rozpoznawania sieci neuronowych, wymagana jest duża liczba przykładów – od tysięcy do milionów obrazów. Taka ilość danych jest niezbędna do efektywnego trenowania modeli i poprawy ich wyników. Im bardziej zróżnicowane obrazy, tym dokładniej sieć neuronowa rozpoznaje obiekty i wykonuje zadania.
Sieci neuronowe to złożone struktury, które naśladują funkcjonowanie ludzkiego mózgu. Składają się z połączonych ze sobą węzłów zwanych neuronami, które przetwarzają informacje. Każdy neuron otrzymuje dane wejściowe, stosuje do nich określone funkcje i przekazuje wynik do kolejnych neuronów. Ten proces pozwala sieciom neuronowym skutecznie rozwiązywać problemy związane z rozpoznawaniem obrazów, przetwarzaniem języka naturalnego i innymi obszarami.
Sieci neuronowe są szeroko stosowane w zastosowaniach praktycznych. Są wykorzystywane w systemach wizyjnych do rozpoznawania obiektów na obrazach, w przetwarzaniu tekstu do automatycznego tłumaczenia i analizy sentymentu, a także w sektorze finansowym do przewidywania zmian rynkowych. Zrozumienie struktury i zasad działania sieci neuronowych otwiera nowe możliwości ich zastosowania w różnych branżach i przyczynia się do rozwoju technologii sztucznej inteligencji.
Struktura i zasady działania prostej sieci neuronowej
Zaczniemy od podstaw prostych sieci neuronowych, stopniowo zagłębiając się w bardziej złożone architektury wielowarstwowe i nowoczesne modele głębokiego uczenia. Wszystkie te systemy opierają się na fundamentalnych zasadach działania, które leżą u podstaw ich działania i uczenia. Zrozumienie podstawowych koncepcji sieci neuronowych jest kluczem do opanowania bardziej złożonych metod i podejść w dziedzinie sztucznej inteligencji i uczenia maszynowego.
Sieci neuronowe to złożone struktury zbudowane z neuronów i połączeń między nimi. Każdy neuron wykonuje określone funkcje i przetwarza dane wejściowe, przekazując wyniki wzdłuż sieci. Połączenia między neuronami zapewniają transmisję informacji i określają sposób przetwarzania i interpretacji danych. Sieci neuronowe są wykorzystywane w różnych dziedzinach, w tym w uczeniu maszynowym, rozpoznawaniu wzorców i analizie danych, ze względu na ich zdolność do wykrywania złożonych wzorców i tworzenia prognoz na podstawie dużych ilości informacji. Wydajność sieci neuronowych czyni je ważnym narzędziem w rozwoju inteligentnych systemów i aplikacji.
- Neuron można postrzegać jako mały program zdolny do wykonywania trzech kluczowych zadań: odbierania danych, przetwarzania ich i przekazywania wyników.
- Połączenia między neuronami mają wagę, która wskazuje siłę wpływu danego neuronu na ostateczną decyzję. Im większa waga, tym większy wkład neuronu.
Najprostsza sieć neuronowa składa się z pojedynczego neuronu. Neuron jest elementem rdzeniowym, który przetwarza dane wejściowe i generuje wartości wyjściowe w oparciu o określone wagi i funkcje aktywacji. Takie proste modele mogą być używane do rozwiązywania podstawowych problemów klasyfikacji i regresji, demonstrując fundamentalne zasady sieci neuronowych. Pomimo swojej prostoty, neuron może skutecznie przetwarzać zależności liniowe i stanowi podstawę bardziej złożonych architektur, takich jak perceptrony wielowarstwowe i głębokie sieci neuronowe. Zrozumienie działania pojedynczego neuronu jest kluczowym krokiem w uczeniu się bardziej złożonych modeli uczenia maszynowego.
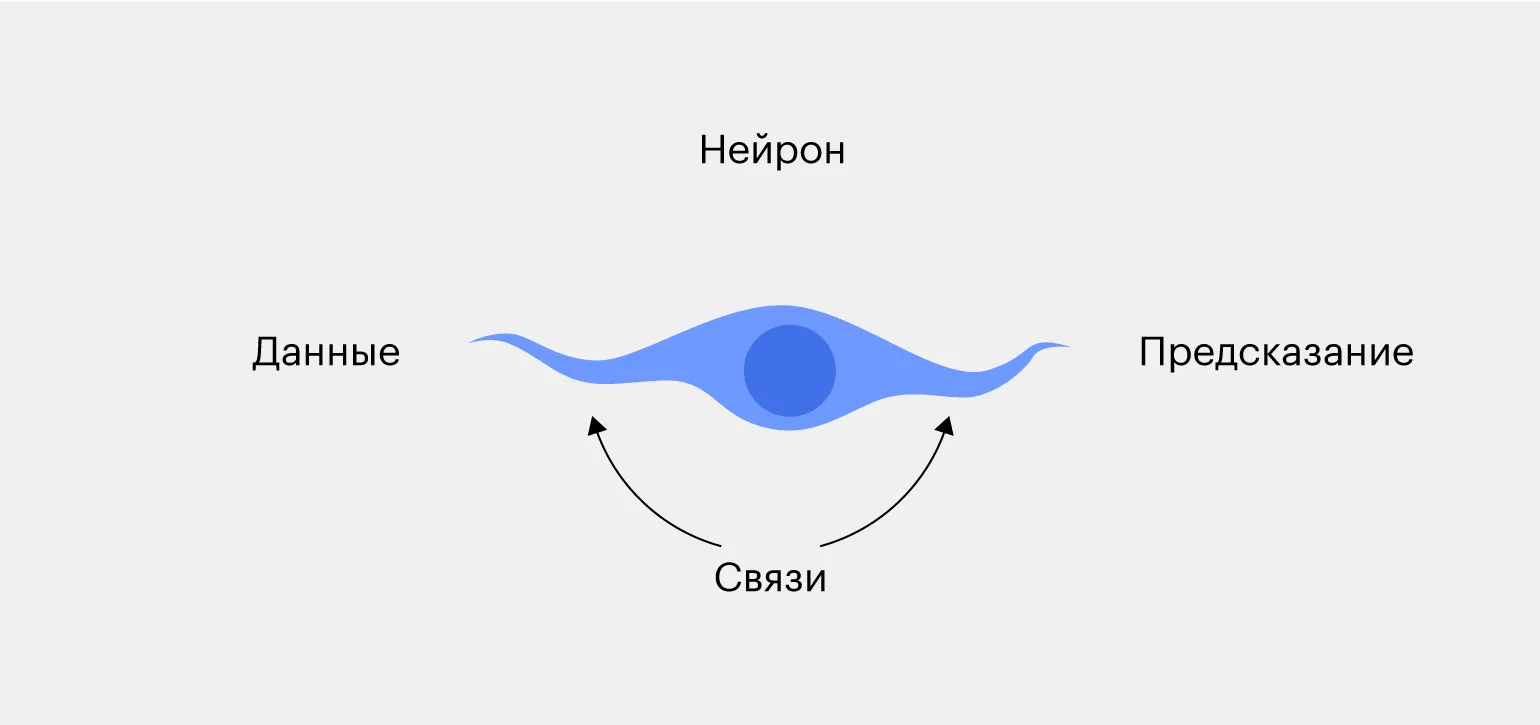
Sieć neuronowa otrzymuje dane wejściowe, takie jak obrazy owoców, takich jak jabłka czy banany. Przetwarza te obrazy, analizując wartości kolorów pikseli. Jeśli w obrazie dominują zielone piksele, sieć neuronowa wnioskuje, że najprawdopodobniej przedstawia on jabłko. Jeśli w obrazie dominują żółte piksele, prawdopodobnie jest to banan. Takie podejście pozwala sieciom neuronowym skutecznie klasyfikować obrazy na podstawie cech koloru.
Jednak ten algorytm ma pewne ograniczenia i nie zawsze wykazuje wysoką dokładność. Na przykład, w jaki sposób sieć neuronowa może odróżnić niedojrzałego zielonego banana od dojrzałego lub rozpoznać żółte jabłko? Sama ocena koloru nie jest wystarczająca do dokładnej identyfikacji. Aby poprawić dokładność rozpoznawania, potrzebne są bardziej zaawansowane metody uwzględniające teksturę, kształt i inne cechy owocu.
Aby poprawić dokładność systemu, zaleca się dodanie dwóch dodatkowych neuronów. Jeden z nich będzie analizował kształt obiektu, a drugi badał jego ogon. To podejście znacząco poprawi jakość przetwarzania danych i zwiększy wydajność sieci neuronowej.
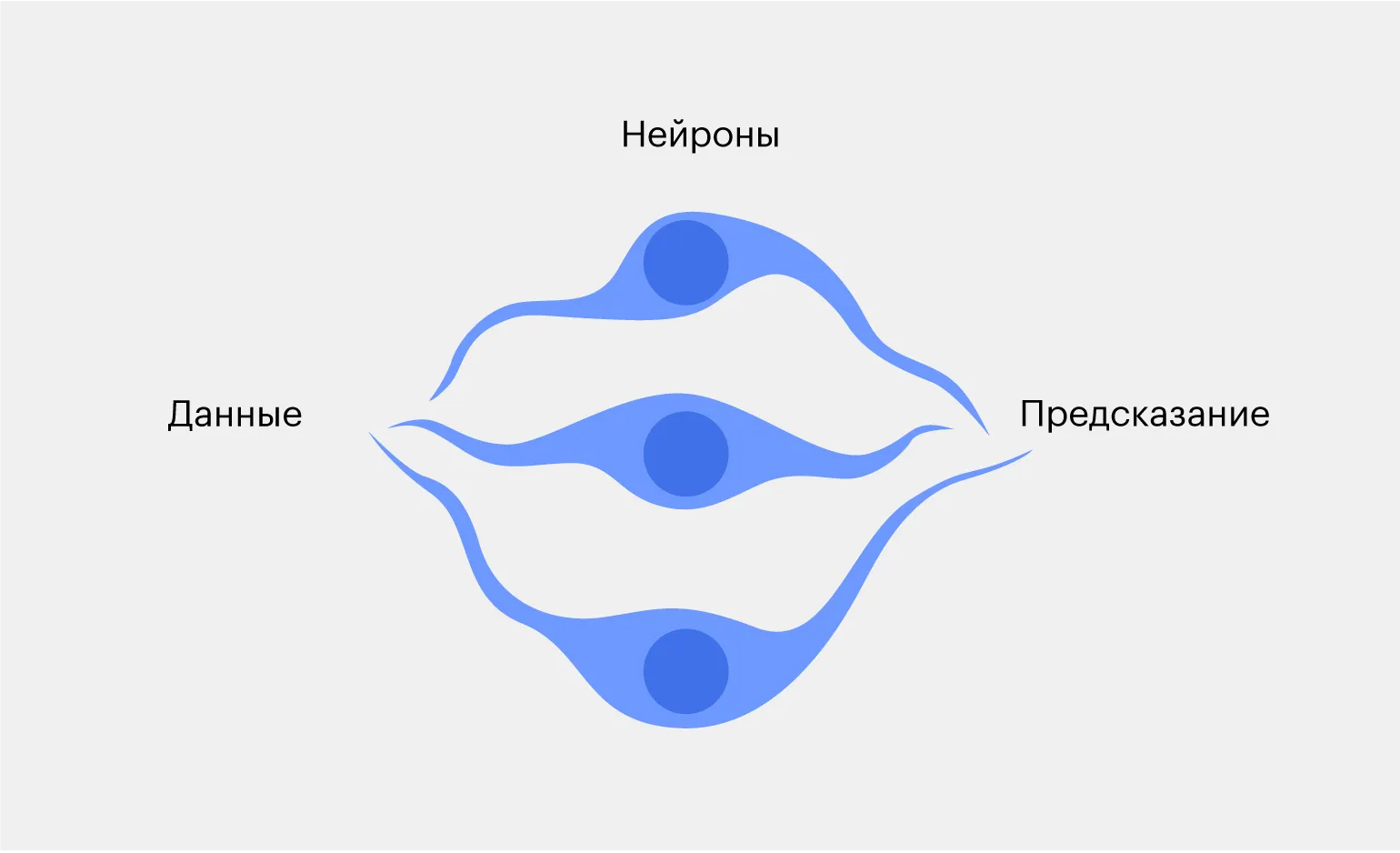
Obraz banana jest przekazywany do trzech sieci neuronowych, z których każda analizuje go według własnych, unikalnych kryteriów i formułuje własne założenia dotyczące treści.
Po przetworzeniu danych powstają trzy możliwe wyniki. Na przykład, dwa neurony mogą zidentyfikować obiekt jako banana, a jeden jako jabłko. Sieć neuronowa analizuje liczbę głosów i podejmuje decyzję na podstawie opinii większości. Takie podejście pozwala na zwiększenie dokładności rozpoznawania obiektów i poprawę wydajności sieci.
Jeśli sieć neuronowa popełni błąd, ważne jest, aby zrozumieć, jak go naprawić. Najpierw należy przeanalizować wynik, aby ustalić przyczynę błędu. Może to być spowodowane niewystarczającą ilością danych, nieprawidłowymi algorytmami, a nawet specyficznymi cechami zadania. Po zidentyfikowaniu problemu należy wprowadzić zmiany w modelu lub danych, na których został on wytrenowany. Warto również rozważyć ponowne wytrenowanie sieci neuronowej z wykorzystaniem nowych danych lub ulepszonych algorytmów. Należy pamiętać, że błędy są częścią procesu, a ich analiza może prowadzić do poprawy wydajności sieci neuronowej w przyszłości.
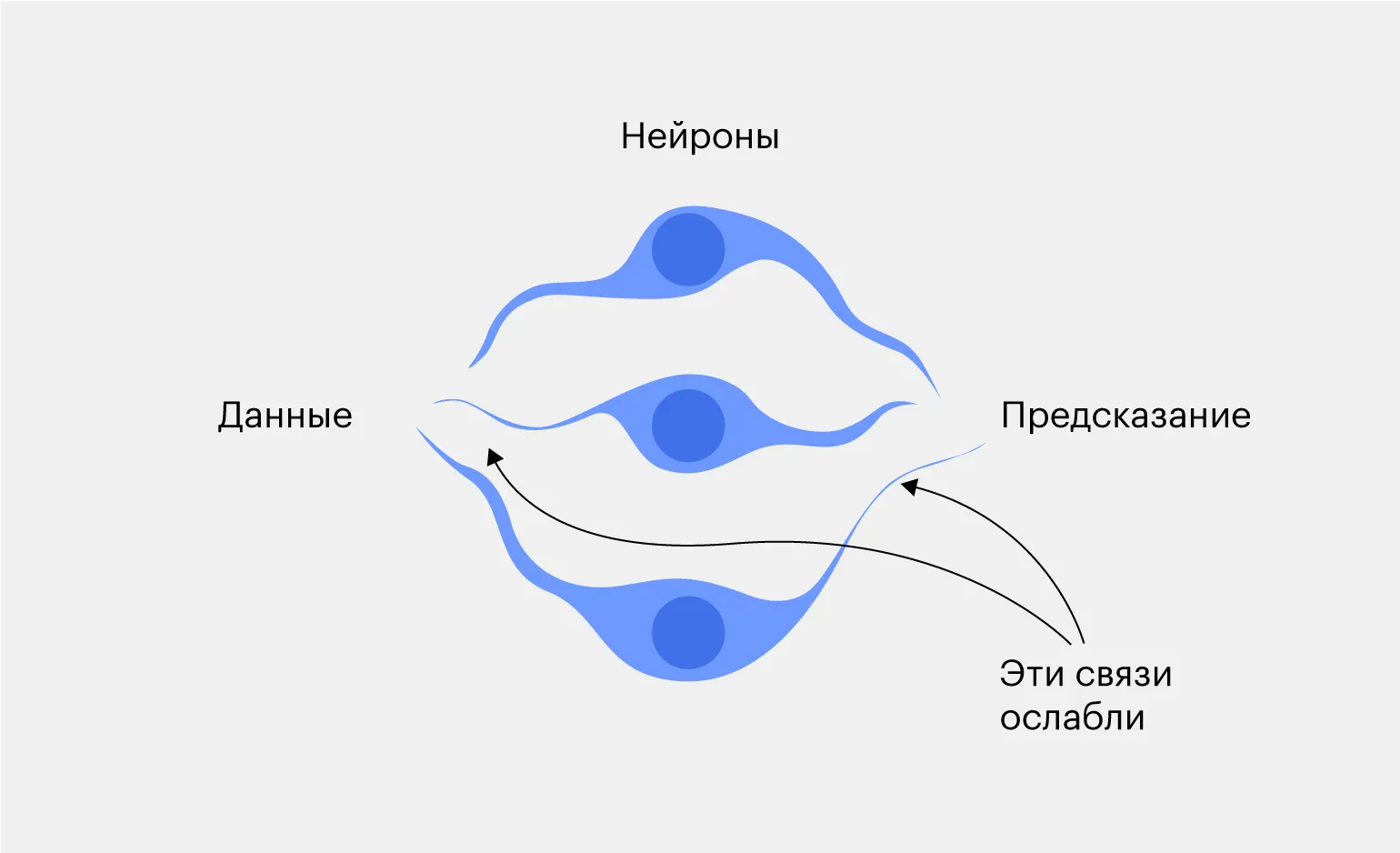
Aby poprawić wyniki, konieczne jest osłabienie wpływu neuronów, które przyczyniły się do błędnego wniosku. Proces ten można postrzegać jako rodzaj mechanicznej „kary” mającej na celu skorygowanie niepoprawnych przewidywań i optymalizację sieci neuronowej.
Połączenia między neuronami określają stopień wpływu każdego neuronu na proces decyzyjny. Słabe połączenie oznacza, że neuron w mniejszym stopniu przyczynia się do końcowego wyniku. Tworzy to analogię do prawdziwego systemu demokratycznego, w którym każdy głos się liczy, ale wpływ poszczególnych uczestników może być różny.
Gdy sieć neuronowa generuje błędne wyniki, zmniejszamy aktywność neuronów, które przyczyniły się do tych wyników. Ten proces jest kluczowym elementem uczenia się w głębokich sieciach neuronowych. Szkolenie polega na dostosowywaniu wag neuronów na podstawie analizy błędów, co pozwala systemowi zwiększyć dokładność przewidywań i dostosować się do nowych danych.
Programujemy sieć neuronową, ale ważne jest, aby zrozumieć, że sztuczna inteligencja nie ogranicza się tylko do tego procesu. Programy uruchamiane w neuronach nie są tworzone ręcznie; powstają w wyniku uczenia sieci neuronowej metodą prób i błędów. Ten proces pozwala systemowi adaptować się i doskonalić swoje możliwości poprzez uczenie się na podstawie danych i doświadczenia, co jest kluczowym aspektem sztucznej inteligencji.
Struktura sieci neuronowej, w tym liczba warstw i neuronów, jest określana przez programistę za pomocą języków programowania, takich jak Python, oraz bibliotek, takich jak TensorFlow. Ta konfiguracja jest kluczowym krokiem w procesie tworzenia i trenowania sieci neuronowej, ponieważ wpływa na zdolność modelu do przetwarzania i analizowania danych. Odpowiednio dobrana architektura sieci neuronowej pozwala na uzyskanie dokładniejszych wyników w zadaniach uczenia maszynowego i głębokiego uczenia.
Badaliśmy, jak neurony są w stanie analizować kolory, kształty i cechy obiektów. Jednak dlaczego sieci neuronowe działają w ten sposób, pozostaje niejasne. Neurony same tworzą algorytmy uczenia się, a naszą rolą jest wskazywanie, co jest poprawne, a co nie. Zrozumienie, jak działają sieci neuronowe, otwiera nowe horyzonty w dziedzinie sztucznej inteligencji i może prowadzić do znaczących przełomów w różnych dziedzinach.
Sieci neuronowe potrafią uwzględniać nietypowe parametry, takie jak cienie czy odbicia obiektów, na przykład owoców. Ta właściwość czyni je podobnymi do ludzkiego mózgu, ponieważ ludzie czasami nie zdają sobie sprawy, jak działa ich umysł. To zachowanie sieci neuronowych podkreśla ich zdolność do przetwarzania złożonych informacji, otwierając nowe horyzonty w dziedzinie sztucznej inteligencji i uczenia maszynowego.
Teraz zwróćmy uwagę na złożone, wielowarstwowe sieci neuronowe, które znacznie rozszerzają możliwości sztucznej inteligencji. Sieci te są zdolne do przetwarzania i analizowania dużych ilości danych, identyfikując złożone wzorce i relacje. Wielowarstwowe sieci neuronowe są wykorzystywane w wielu dziedzinach, takich jak przetwarzanie obrazu, rozpoznawanie mowy i analiza tekstu, co czyni je niezbędnymi narzędziami w nowoczesnej sztucznej inteligencji. Ich zdolność do uczenia się na podstawie dużych zbiorów danych pozwala im osiągać wysoką dokładność i wydajność w rozwiązywaniu złożonych problemów. Struktura wielowarstwowych sieci neuronowych: jak to działa? Wielowarstwowe sieci neuronowe, zwane również głębokimi sieciami neuronowymi, są niezbędnym narzędziem w sztucznej inteligencji. Sieci te składają się z wielu warstw, z których każda wykonuje określone funkcje przetwarzania danych. Dzięki swojej architekturze, wielowarstwowe sieci neuronowe są w stanie skutecznie wyodrębniać złożone wzorce i reprezentacje z dużych wolumenów informacji. To czyni je niezbędnymi w takich dziedzinach jak widzenie komputerowe, przetwarzanie języka naturalnego i rozpoznawanie mowy. Zastosowanie głębokich sieci neuronowych otwiera nowe horyzonty dla rozwoju inteligentnych aplikacji i technologii zdolnych do rozwiązywania złożonych problemów.
Warstwa wejściowa to punkt wyjścia, w którym sieć neuronowa przyjmuje dane, w tym obrazy, wartości liczbowe i tekst. Stanowi ona podstawę do dalszego przetwarzania informacji. Warstwa wyjściowa z kolei odpowiada za prezentację końcowych wyników przetwarzania danych. Warstwy pośrednie, zwane warstwami ukrytymi, odgrywają kluczową rolę w analizie danych, umożliwiając głębokie przetwarzanie i identyfikację ukrytych wzorców. Każda z tych warstw przyczynia się do wydajności sieci neuronowej, co czyni je kluczowymi dla uzyskania dokładnych i wiarygodnych wyników.

Wielowarstwowa sieć neuronowa działa podobnie do prostej sieci neuronowej, ale z istotną różnicą: przetwarza dane na wielu warstwach. Ta wielowarstwowa transformacja umożliwia głębszą analizę informacji i poprawia jakość wyników. Dzięki swojej architekturze, wielowarstwowe sieci neuronowe są w stanie identyfikować złożone wzorce i zależności w danych, co czyni je niezbędnymi w zadaniach uczenia maszynowego i sztucznej inteligencji. Efektywne wykorzystanie takich sieci otwiera nowe horyzonty w analizie dużych wolumenów informacji i rozwiązywaniu złożonych problemów związanych z klasyfikacją, rozpoznawaniem obrazów i przetwarzaniem języka naturalnego.
Liczba połączeń między neuronami w tym modelu może wydawać się zniechęcająca, ale to właśnie ta złożoność pozwala sieci skutecznie identyfikować złożone wzorce w danych. Dzięki tym licznym połączeniom neurony są w stanie przetwarzać informacje na różnych poziomach, co ułatwia głębszą analizę i dokładne prognozowanie. Zdolność sieci neuronowych do rozpoznawania wzorców czyni je niezbędnymi w takich dziedzinach jak uczenie maszynowe, sztuczna inteligencja i analiza dużych zbiorów danych. Warstwy ukryte w sieciach neuronowych odgrywają kluczową rolę w przetwarzaniu danych wejściowych, umożliwiając wykrywanie złożonych wzorców i niuansów. Na przykład, różnicę między jabłkami a bananami można analizować na podstawie różnych cech, takich jak kolor, tekstura i kształt. Warstwy ukryte pozwalają sieci neuronowej przetwarzać te cechy na różnych poziomach abstrakcji, zwiększając skuteczność modelu w klasyfikowaniu i rozpoznawaniu obiektów. Wykorzystanie warstw ukrytych znacząco poprawia dokładność i głębokość analizy danych, co stanowi istotny aspekt rozwoju nowoczesnych technologii uczenia maszynowego.
- Sieć neuronowa odbiera obraz o wymiarach 200 na 400 pikseli, czyli 80 000 pikseli, z których każdy jest przekazywany do wszystkich neuronów wejściowych.
- Warstwa wejściowa wstępnie przetwarza obraz, określając ogólny kształt obiektu, i przekazuje przetworzone dane do warstwy ukrytej.
- Pierwsza warstwa ukryta wykonuje dodatkowe przetwarzanie, na przykład rozpoznaje kolor obiektu, i przekazuje wyniki dalej.
- Druga warstwa ukryta analizuje szczegóły obiektu, co przyczynia się do dokładniejszej klasyfikacji.
- Gdy dane docierają do warstwy wyjściowej, sieć neuronowa formułuje hipotezę opartą na całym poprzednim przetwarzaniu.
Pomimo zwiększonej złożoności mechanizmu, sieć neuronowa osiągnęła nowy poziom możliwości intelektualnych. Pozwala to na efektywne rozwiązywanie bardziej złożonych problemów, w tym rozpoznawanie wzorców i automatyczne generowanie tekstu. Nowoczesne sieci neuronowe osiągają imponujące wyniki w analizie danych i tworzeniu treści, znacząco rozszerzając ich zastosowanie w różnych dziedzinach, takich jak sztuczna inteligencja, przetwarzanie języka naturalnego i widzenie komputerowe.
Aby osiągnąć wyższy poziom inteligencji w sieci neuronowej, samo zwiększenie liczby warstw nie wystarczy. Chociaż dodanie kolejnych warstw może pomóc w zmniejszeniu liczby błędów, nie jest to rozwiązanie uniwersalne. Nawet przy tysiącach warstw ryzyko wystąpienia błędów pozostaje. Potrzebne są bardziej kompleksowe podejścia, w tym optymalizacja architektury, ulepszone algorytmy uczenia się oraz wykorzystanie wysokiej jakości danych treningowych. Środki te mogą znacząco poprawić wydajność sieci neuronowych i zminimalizować prawdopodobieństwo wystąpienia błędów w ich działaniu.
Osiągnięcie kolejnego poziomu „inteligencji” wymaga zastosowania algorytmów głębokiego uczenia. W kolejnych sekcjach szczegółowo omówimy te algorytmy. Zanim je opiszemy, najpierw zrozumiemy, jak głębokie uczenie się i sieci neuronowe są ze sobą powiązane.
Głębokie uczenie się i sieci neuronowe: podstawowe koncepcje
Sieci neuronowe są kluczowym narzędziem sztucznej inteligencji, modelującym funkcjonowanie ludzkiego mózgu. Głębokie uczenie się obejmuje różnorodne metody i techniki, które pozwalają na efektywne trenowanie tych sieci. Technologie te są wykorzystywane w wielu dziedzinach, takich jak przetwarzanie języka naturalnego, rozpoznawanie obrazów i predykcja danych, co czyni je integralną częścią nowoczesnych rozwiązań AI. Rozwój sieci neuronowych i metod głębokiego uczenia się otwiera nowe horyzonty dla automatyzacji i optymalizacji procesów w różnych branżach.
Terminy „sieć neuronowa” i „głębokie uczenie się” są często postrzegane jako synonimy, ale istnieje między nimi istotna różnica. Sieć neuronowa to architektura składająca się z wielu oddziałujących na siebie neuronów, które przetwarzają dane wejściowe i generują dane wyjściowe. Na przykład sieci neuronowe mogą skutecznie rozróżniać obiekty na obrazach, analizując ich cechy i strukturę. Głębokie uczenie (Deep Learning) to metoda wykorzystująca wielowarstwowe sieci neuronowe do rozwiązywania złożonych problemów, takich jak rozpoznawanie obrazów i przetwarzanie języka naturalnego. Zrozumienie tych różnic pomoże lepiej poruszać się po nowoczesnych technologiach sztucznej inteligencji i ich zastosowaniach w różnych dziedzinach.
Głębokie uczenie (Deep Learning) to metoda oparta na tworzeniu wielowarstwowych sieci neuronowych, która umożliwia efektywne rozwiązywanie złożonych problemów, takich jak klasyfikacja obrazów, rozpoznawanie mowy i generowanie tekstu. Według badania opublikowanego w czasopiśmie „Nature”, wykorzystanie głębokiego uczenia (Deep Learning) znacząco poprawiło dokładność w kluczowych obszarach, takich jak diagnostyka medyczna i pojazdy autonomiczne. Potwierdza to jego znaczenie i potencjał w nowoczesnej technologii, otwierając nowe horyzonty dla innowacyjnych rozwiązań.
Sieci neuronowe stanowią kluczowy element głębokiego uczenia (Deep Learning), bez którego rozwój nowoczesnych algorytmów uczenia maszynowego byłby niemożliwy. Stanowią one fundamentalną architekturę, na której opiera się wiele najnowocześniejszych technologii i aplikacji w tej dziedzinie. Aby uzyskać bardziej szczegółowe informacje na temat sieci neuronowych i ich roli w uczeniu maszynowym, zalecamy lekturę naszego artykułu poświęconego temu tematowi.
Sieci neuronowe i głębokie uczenie to powiązane, ale odrębne koncepcje, które są niezbędne dla rozwoju technologii sztucznej inteligencji. Sieci neuronowe to architektury inspirowane ludzkim mózgiem, wykorzystywane do przetwarzania i analizy danych. Głębokie uczenie z kolei to podzbiór uczenia maszynowego, który wykorzystuje wielowarstwowe sieci neuronowe do rozwiązywania złożonych problemów, takich jak rozpoznawanie obrazów, przetwarzanie języka naturalnego i wiele innych. Technologie te stale się rozwijają, otwierając nowe możliwości w dziedzinach od medycyny po finanse.
Metody uczenia sieci neuronowych: podstawy
Sieci neuronowe to potężne narzędzia do analizy i prognozowania danych. W tym artykule szczegółowo omówimy podstawowe aspekty uczenia sieci neuronowych, wykorzystując jako przykład przewidywanie cen biletów lotniczych. Zrozumienie działania sieci neuronowych pozwala nam identyfikować ukryte wzorce w danych i formułować trafne prognozy, co jest szczególnie ważne w branży lotniczej, gdzie wahania cen mogą zależeć od wielu czynników. Przeanalizujemy, jak przygotowanie danych, architektura sieci i trenowanie wpływają na jakość prognoz.
- Dane wejściowe: data lotu, miejsce wylotu i cel podróży.
- Dane wyjściowe: przewidywana cena biletu lotniczego.
Posiadamy historyczne dane cenowe, które wykorzystamy do trenowania sieci neuronowej. Dane te pozwolą modelowi skutecznie analizować trendy i przewidywać zmiany rynkowe. Wykorzystanie informacji historycznych jest kluczowym krokiem w procesie trenowania, ponieważ pomaga poprawić dokładność prognoz i zwiększyć wydajność sieci neuronowej.
Nasza sieć neuronowa składa się z trzech warstw: warstwy wejściowej zawierającej trzy neurony, dwóch warstw ukrytych, z których każda zawiera cztery neurony, oraz warstwy wyjściowej z jednym neuronem. Taka struktura umożliwia wydajne przetwarzanie i analizę danych, zapewniając wysoką dokładność w zadaniach uczenia maszynowego. Warstwa wejściowa odbiera dane, warstwy ukryte przetwarzają je i identyfikują złożone wzorce, a warstwa wyjściowa generuje wynik końcowy. Użycie wielu warstw ukrytych znacznie zwiększa możliwości uczenia się i adaptacji sieci neuronowej, czyniąc ją bardziej skuteczną w rozwiązywaniu różnorodnych problemów. Trening sieci neuronowej rozpoczyna się od danych wejściowych, które są wykorzystywane do formułowania prognoz cenowych. Jeśli prognoza jest bliska wartości rzeczywistej, połączenia między neuronami, które przyczyniają się do tego wyniku, ulegają wzmocnieniu. W przeciwnym razie, jeśli prognoza jest błędna, połączenia te ulegają osłabieniu. Ten proces adaptacji pozwala sieci neuronowej ulepszać swoje prognozy w czasie, zwiększając dokładność i niezawodność analizy cen.
Terminy „wzmocnienia” i „rozluźnienia” połączeń w sieciach neuronowych odnoszą się do zmieniających się wag, które są wartościami liczbowymi, takimi jak 2, 5 lub 19,3. Gdy sieć neuronowa dokonuje prawidłowej prognozy, waga połączenia wzrasta, poprawiając dokładność modelu. Gdy prognoza jest nieprawidłowa, waga maleje, pozwalając sieci neuronowej dostosować parametry w celu uzyskania lepszych wyników. Początkowe wagi są ustawiane losowo, a następnie dostosowywane w trakcie procesu uczenia, co pozwala modelowi efektywnie przetwarzać i analizować dane.
Po tysiącach iteracji sieć neuronowa zaczyna generować dokładniejsze wyniki, a po milionie iteracji jest w stanie wykonywać zadania na poziomie doświadczonego agenta turystycznego. Ten poziom uczenia się pozwala algorytmowi nie tylko przetwarzać żądania użytkowników, ale także oferować optymalne rozwiązania w oparciu o analizę dużych wolumenów danych. Otwiera to nowe horyzonty dla zastosowania technologii w sektorze turystycznym i poprawia obsługę klienta.
Sieć neuronowa pomyślnie ukończyła proces uczenia. Teraz, po wprowadzeniu dowolnej daty i celu podróży, jest w stanie precyzyjnie określić cenę biletu z minimalnym błędem.
Uczenie nadzorowane to metoda, w której dane historyczne stanowią podstawę do uczenia sieci neuronowej. W tym procesie sieć neuronowa analizuje dostarczone dane, wyodrębniając z nich wzorce i zależności. Takie podejście pozwala na efektywne rozwiązywanie problemów klasyfikacji i regresji, znacznie poprawiając dokładność prognoz i decyzji.
Uczenie nadzorowane może napotykać pewne ograniczenia, szczególnie w sytuacjach, gdy nie ma etykiet do uczenia. Na przykład, jak można nauczyć sieć neuronową gry w Tetrisa bez predefiniowanych danych? W takich przypadkach konieczne jest zastosowanie alternatywnych metod, takich jak uczenie nienadzorowane lub uczenie przez wzmacnianie, które pozwalają systemowi samodzielnie wydobywać wiedzę z otoczenia i podejmować decyzje w oparciu o doświadczenie. Te podejścia otwierają nowe możliwości rozwoju efektywnych algorytmów i technologii zdolnych do rozwiązywania problemów, w których tradycyjne metody zawodzą.
Uczenie bez nadzoru to metoda przeciwna, w której sieć neuronowa samodzielnie określa akceptowalne wyniki. Choć może się to wydawać nietypowe, podejście to okazało się bardzo skuteczne w praktyce. Metoda ta pozwala modelom identyfikować ukryte wzorce i struktury w danych bez wcześniejszego etykietowania, co czyni je szczególnie przydatnymi do analizy dużych wolumenów informacji. Uczenie bez nadzoru jest aktywnie wykorzystywane w różnych dziedzinach, w tym w klasteryzacji, redukcji wymiarowości i wykrywaniu anomalii, przyczyniając się do głębszego zrozumienia danych i lepszego podejmowania decyzji.
Wyobraźmy sobie, że chcemy segmentować użytkowników witryny z hostingiem wideo, aby zapewnić im odpowiednie treści. Chociaż zadanie to jest trudne do wykonania ręcznie, sieć neuronowa może skutecznie sobie z nim poradzić, analizując dane dotyczące oglądanych filmów, polubień i subskrypcji. Wykorzystanie technologii uczenia maszynowego pozwala na dokładniejsze zrozumienie preferencji użytkowników, co z kolei przyczynia się do lepszego doświadczenia użytkownika i większego zaangażowania. Sieć neuronowa potrafi identyfikować wzorce w zachowaniach widzów, otwierając drogę do spersonalizowanych rekomendacji i zwiększając retencję odbiorców. Wykorzystując te dane, sieć neuronowa może łączyć użytkowników o podobnych zainteresowaniach, przyczyniając się do stworzenia skutecznego systemu rekomendacji. Poprawia to personalizację treści i zwiększa zaangażowanie odbiorców, zwiększając ich zadowolenie i lojalność. Uczenie nadzorowane i nienadzorowane to dwie główne metody wykorzystywane w trenowaniu sieci neuronowych. Tworzenie złożonych systemów, takich jak ChatGPT, wymaga wykorzystania nowoczesnych algorytmów głębokiego uczenia. Podejścia te umożliwiają efektywne przetwarzanie i analizę dużych wolumenów danych, co jest kluczem do tworzenia wysokiej jakości i funkcjonalnych modeli. Wykorzystanie zaawansowanych technologii i metod w trenowaniu sieci neuronowych otwiera nowe możliwości rozwoju inteligentnych systemów zdolnych do naturalnej interakcji z użytkownikami.
Przegląd algorytmów głębokiego uczenia: Co musisz wiedzieć
Głębokie uczenie rozwija się dynamicznie z roku na rok, a na rynku pojawiają się nowe algorytmy mające na celu rozwiązanie różnorodnych problemów. Jednak wciąż nie ma uniwersalnej metody, która skutecznie poradziłaby sobie ze wszystkimi problemami. Obecnie stosuje się różne podejścia, takie jak splotowe sieci neuronowe, które doskonale sprawdzają się w przetwarzaniu obrazu, oraz rekurencyjne sieci neuronowe stosowane w analizie tekstu. Różnorodność podejść pozwala na znalezienie optymalnych rozwiązań dla konkretnych problemów, co czyni głębokie uczenie potężnym narzędziem w różnych dziedzinach, w tym w dziedzinie widzenia komputerowego i przetwarzania języka naturalnego.
Splotowe sieci neuronowe (CNN) odgrywają kluczową rolę w dziedzinie widzenia komputerowego, zapewniając skuteczną analizę i interpretację danych wizualnych. Sieci te zostały zaprojektowane specjalnie do przetwarzania obrazów i strumieni wideo, umożliwiając im wykrywanie złożonych wzorców i cech. Do kluczowych zastosowań CNN należą rozpoznawanie obiektów, klasyfikacja obrazów i segmentacja, co czyni je niezbędnymi w takich dziedzinach jak medycyna, motoryzacja i bezpieczeństwo. Dzięki możliwości trenowania na dużych wolumenach danych, splotowe sieci neuronowe stale ewoluują, zwiększając dokładność i wydajność widzenia komputerowego. Splotowe sieci neuronowe (CNN) działają poprzez integrację dodatkowych warstw splotowych ze swoją architekturą, ułatwiając głębszą analizę obrazu. Każda warstwa splotowa wykorzystuje filtry do identyfikacji różnych elementów obrazu, od prostych konturów po złożone tekstury. To wielowarstwowe podejście pozwala sieciom neuronowym CNN efektywnie przetwarzać dane wizualne, poprawiając dokładność rozpoznawania obiektów i klasyfikacji obrazów. Ze względu na możliwość automatycznego wyodrębniania cech, sieci CNN są szeroko stosowane w takich dziedzinach jak widzenie komputerowe, analiza obrazów i wideo oraz głębokie uczenie.
Pierwsza warstwa splotowa sieci neuronowej ma na celu wykrywanie krawędzi i narożników obiektów na obrazie. Z każdą kolejną warstwą przetwarzane są coraz bardziej złożone struktury, w tym kształty i tekstury. Ostatecznie ostatnia warstwa integruje wszystkie zebrane informacje i tworzy prognozę dotyczącą zawartości obrazu. To podejście pozwala głębokim sieciom neuronowym skutecznie analizować dane wizualne i poprawiać jakość rozpoznawania obiektów.
Rekurencyjne sieci neuronowe (RNN) są ważnym narzędziem do przetwarzania danych sekwencyjnych, w tym tekstu i szeregów czasowych. Ze względu na swoją architekturę, sieci RNN mogą zapamiętywać informacje o poprzednich elementach, co znacznie poprawia dokładność predykcji kolejnych elementów w sekwencji. Sieci te są aktywnie wykorzystywane w takich dziedzinach jak przetwarzanie języka naturalnego, rozpoznawanie mowy i analiza szeregów czasowych. Wykorzystując sieci neuronowe rekurencyjne (RNN), badacze i programiści mogą budować modele, które efektywnie przetwarzają i analizują dane pod kątem ich sekwencji i kontekstu, co czyni je niezbędnymi w nowoczesnych zadaniach uczenia maszynowego. Architektura rekurencyjnych sieci neuronowych (RNN) to struktura sekwencyjna, podobna do sznura koralików, gdzie każdy koralik reprezentuje fragment informacji, na przykład słowo. Te relacje dają modelom możliwość tworzenia skojarzeń i uzyskiwania głębszego kontekstu. Rekurencyjne sieci neuronowe odgrywają kluczową rolę w przetwarzaniu danych sekwencyjnych, takich jak tekst i szeregi czasowe, ze względu na ich zdolność do zapamiętywania informacji o poprzednich elementach sekwencji. To sprawia, że sieci RNN są niezbędne w zadaniach związanych z analizą języka naturalnego i przewidywaniem sekwencji.
Jedną z najpopularniejszych form rekurencyjnych sieci neuronowych (RNN) są sieci pamięci długoterminowej i krótkoterminowej (LSTM). Sieci te mają zdolność do długotrwałego przechowywania informacji w pamięci, co czyni je skutecznymi w przetwarzaniu danych sekwencyjnych. Sieci LSTM są szeroko stosowane w różnych dziedzinach, w tym w przetwarzaniu języka naturalnego i systemach generowania tekstu, takich jak ChatGPT. Dzięki zdolności do zapamiętywania poprzednich wiadomości, sieci LSTM zapewniają dokładniejsze i trafniejsze kontekstowo odpowiedzi, znacząco poprawiając komfort użytkowania.
Generatywne sieci przeciwstawne (GAN) to rewolucyjna technologia, która znacząco zmienia podejście do kreatywności. Algorytmy te potrafią generować obrazy, muzykę i poezję, naśladując styl różnych autorów. Korzystając z sieci GAN, artyści i muzycy mogą eksperymentować z nowymi formami sztuki, tworząc unikalne dzieła w oparciu o analizę istniejących stylów. Technologia ta otwiera ogromne możliwości dla branży kreatywnej, umożliwiając połączenie sztucznej inteligencji z ludzką kreatywnością. Sieci GAN stają się niezbędnym narzędziem dla osób poszukujących innowacji w sztuce i projektowaniu.
Generatywne sieci konfrontacyjne (GAN) opierają się na interakcji dwóch sieci neuronowych: generatora i dyskryminatora. Generator, działając jako „artysta”, tworzy nowe dzieła, podczas gdy dyskryminator, działając jako „krytyk”, ocenia je, ustalając, czy zostały stworzone przez człowieka, czy maszynę. Ten proces rywalizacji między dwiema sieciami sprzyja ich ciągłemu doskonaleniu, pozwalając generatorowi tworzyć bardziej realistyczne obrazy, a dyskryminatorowi – poprawiać zdolność rozpoznawania podróbek. W rezultacie sieci GAN stają się potężnym narzędziem w dziedzinie sztucznej inteligencji, zdolnym do generowania wysokiej jakości treści i otwierania nowych możliwości w różnych dziedzinach, takich jak sztuka, moda i rozrywka.
To podejście pozwala sieciom neuronowym szybko adaptować się i uczyć bez znacznego wysiłku ze strony programistów. Samo wykorzystanie algorytmów uczenia maszynowego sprawia, że proces ten jest bardziej wydajny i mniej pracochłonny.
Synergia algorytmów głębokiego uczenia to potężne narzędzie do poprawy wyników w różnych dziedzinach. Łączenie wielu algorytmów może poprawić dokładność prognoz i wydajność przetwarzania danych. Na przykład, integracja sieci neuronowych z innymi metodami uczenia maszynowego może prowadzić do dokładniejszych wniosków i udoskonalonej analizy. Stosując podejście synergistyczne, naukowcy i praktycy mogą wydobywać nowe spostrzeżenia z dużych wolumenów danych, otwierając nowe horyzonty dla rozwoju innowacyjnych rozwiązań i technologii. Synergia w głębokich sieciach neuronowych nie tylko zwiększa ich wydajność, ale także rozszerza ich zastosowanie w takich dziedzinach jak medycyna, finanse i automatyka.
Algorytmy głębokiego uczenia można skutecznie łączyć, aby tworzyć bardziej zaawansowane rozwiązania. Na przykład, połączenie generatywnych sieci przeciwstawnych (GAN) i rekurencyjnych sieci neuronowych (RNN) pozwala na tworzenie sieci neuronowych, które nie tylko generują treści, ale także uwzględniają wcześniejsze interakcje. Dzięki temu systemy stają się bardziej interaktywne i inteligentne, znacząco rozszerzając ich możliwości w różnych dziedzinach, takich jak pisanie, muzyka, sztuka i wiele innych. To podejście zwiększa potencjał głębokiego uczenia się, umożliwiając tworzenie bardziej adaptacyjnych i inteligentnych rozwiązań, które mogą reagować na zmiany danych i żądania użytkowników.
Głębokie uczenie się stale rozwija, otwierając nowe horyzonty rozwiązywania złożonych problemów w różnych branżach. Ten obszar sztucznej inteligencji wykazuje znaczny potencjał, umożliwiając efektywne przetwarzanie dużych wolumenów danych i wydobywanie z nich użytecznych informacji. Ciągłe innowacje w algorytmach i architekturach sieci neuronowych przyczyniają się do poprawy dokładności i szybkości przetwarzania. Dzięki temu głębokie uczenie się staje się kluczowym narzędziem w takich dziedzinach jak medycyna, finanse, przemysł motoryzacyjny i wiele innych.
Zastosowania głębokiego uczenia się: od medycyny do rozrywki
Głębokie uczenie się stało się integralną częścią naszego codziennego życia, ale nie może całkowicie zastąpić wszystkich zawodów. Głównym powodem jest ograniczona moc obliczeniowa współczesnych komputerów, która utrudnia rozwój algorytmów. Pomimo postępów w dziedzinie sztucznej inteligencji i uczenia maszynowego, wiele zadań wymaga ludzkiej inteligencji i kreatywności. Głębokie uczenie skutecznie radzi sobie z analizą dużych wolumenów danych i rozpoznawaniem wzorców, ale jego zastosowanie jest wciąż ograniczone. W przyszłości oczekuje się zwiększenia mocy obliczeniowej, co pozwoli algorytmom na głębszą integrację z różnymi dziedzinami i rozszerzenie ich możliwości.
Niemniej jednak istnieje wiele obszarów, w których technologie głębokiego uczenia wykazują wyraźne zalety. Technologie te znajdują zastosowanie w różnych branżach, w tym w opiece zdrowotnej, finansach, motoryzacji i produkcji. Głębokie uczenie umożliwia analizę dużych wolumenów danych, lepsze prognozowanie i automatyzację procesów. Dzięki swoim możliwościom technologie te przyczyniają się do zwiększenia wydajności i trafności podejmowania decyzji, co czyni je niezbędnymi dla nowoczesnych firm.
Układy scalone do gadżetów. W ostatnich latach firmy aktywnie wdrażają algorytmy głębokiego uczenia w swoich urządzeniach, znacząco zwiększając ich wydajność i funkcjonalność. Na przykład NVIDIA zademonstrowała, jak sieci neuronowe mogą poprawić wydajność kart graficznych, zapewniając płynniejszą rozgrywkę. Podobnie Apple twierdzi, że ich procesory integrują sieci neuronowe, które poprawiają wydajność smartfonów. Chociaż niektórzy mogą postrzegać to jako chwyt marketingowy, wielu ekspertów potwierdza realność i skuteczność tych technologii. Integracja głębokiego uczenia z układami scalonymi otwiera nowe horyzonty dla gadżetów, czyniąc je inteligentniejszymi i lepiej reagującymi na potrzeby użytkowników.
Nowoczesne technologie w branży gier zapewniają wciągające doświadczenia, w których interakcje z postaciami niezależnymi (NPC) stają się bardziej wiarygodne. Wprowadzenie ChatGPT zainspirowało deweloperów do tworzenia dialogów zaskakujących graczy swoją naturalnością i głębią. Wykorzystanie sieci neuronowych w grach otwiera nowe możliwości kreatywności i zaangażowania użytkownika, umożliwiając tworzenie unikalnych scenariuszy i wzbogacając ogólne wrażenia z gry. Takie innowacje nie tylko zwiększają zainteresowanie grami, ale także wzbogacają interakcję między graczami a światem gry.
Medycyna Chociaż sieci neuronowe nie są w stanie postawić jednoznacznej diagnozy, odgrywają one kluczową rolę w diagnozowaniu chorób, znacznie ułatwiając pracę lekarzy. Startupy takie jak Woebot stworzyły innowacyjnych wirtualnych psychologów, którzy zapewniają wsparcie i porady, dzięki czemu technologie te są przydatne w poprawie zdrowia psychicznego. Zastosowanie sieci neuronowych w medycynie otwiera nowe horyzonty w zakresie poprawy skuteczności diagnostyki i terapii, a także ułatwia dostęp do opieki psychoterapeutycznej.
Asystenci cyfrowi. Sieci neuronowe są aktywnie wykorzystywane do tworzenia wysoce efektywnych asystentów cyfrowych, które znacznie upraszczają proces przygotowywania prezentacji, nagrywania filmów edukacyjnych i filtrowania połączeń spamowych. Przykładem jest Tinkoff Bank, który wdrożył automatyczną sekretarkę zdolną do obsługi połączeń od klientów. To rozwiązanie nie tylko poprawia jakość obsługi, ale także optymalizuje obsługę klienta, pozwalając personelowi skupić się na bardziej złożonych zapytaniach. Zastosowanie sieci neuronowych w tym obszarze otwiera nowe możliwości dla firm, poprawiając zaangażowanie klientów i zwiększając ogólną wydajność operacyjną.
Kluczowe punkty do zapamiętania
Dzisiaj omówiliśmy kluczowe aspekty, które należy wziąć pod uwagę. Skupiliśmy się na głównych tematach naszych badań. Przeanalizowaliśmy ważne czynniki wpływające na nasze wyniki i podkreśliliśmy kluczowe ustalenia. Te aspekty pomogą lepiej zrozumieć temat i utworzyć dalsze kroki do pogłębionych badań.
- Głębokie uczenie to metoda, która pozwala komputerom wykonywać złożone zadania, takie jak rozpoznawanie obiektów, na przykład odróżnianie jabłek od bananów.
- Głębokie uczenie opiera się na sieciach neuronowych, które działają podobnie do ludzkiego mózgu, przetwarzając i analizując informacje.
- Struktura sieci neuronowej obejmuje neurony połączone połączeniami, które umożliwiają przesyłanie przetworzonych informacji z jednego neuronu do drugiego.
- Trening sieci neuronowej odbywa się poprzez proces nagrody: neurony, które prowadzą do prawidłowych wyników, są wzmacniane, a nieskuteczne połączenia są osłabiane.
- Sieci neuronowe mogą być proste (jedna warstwa neuronów) i wielowarstwowe, te ostatnie mogą składać się z kilku warstw.
- Wielowarstwowa sieć neuronowa zawiera trzy typy warstw: wejściową, do początkowego przetwarzania danych; ukrytą, do dalszego przetwarzania; i wynik, który generuje ostateczną prognozę.
- Istnieją dwie główne metody szkolenia sieci neuronowych: uczenie nadzorowane, w którym prognozy są porównywane z rzeczywistymi wynikami, oraz uczenie bez nadzoru, w którym sieć samodzielnie poszukuje poprawnych odpowiedzi.
- Do rozwiązywania złożonych problemów wykorzystuje się różne algorytmy głębokiego uczenia, wśród których najpopularniejsze to splotowe sieci neuronowe, modele rekurencyjne i generatywne modele przeciwstawne.
- Sieci neuronowe są szeroko stosowane w różnych dziedzinach, w tym w grach, asystentach głosowych i diagnostyce medycznej.
Bądź na bieżąco z najnowszymi osiągnięciami w programowaniu i technologii, subskrybując nasz kanał na Telegramie. Znajdziesz tam aktualne wiadomości, przydatne wskazówki i ciekawe materiały, które pomogą Ci rozwijać się w tej dynamicznej dziedzinie. Nie przegap okazji, aby być na bieżąco z najnowszymi trendami i aktualizacjami!
Zalecamy zapoznanie się z dodatkowymi materiałami, które pomogą Ci pogłębić wiedzę i poszerzyć zrozumienie tematu. Te zasoby zawierają istotne informacje i rekomendacje, które mogą być przydatne w nauce. Jesteśmy przekonani, że będą one doskonałym uzupełnieniem Twojego doświadczenia.
- Zamknięta sztuczna inteligencja od OpenAI: Odkrywanie potencjału sieci neuronowej GPT-4
- Test: Raper, muzyk klasyczny czy sieć neuronowa? Sprawdź swoją wiedzę!
- Biblioteka TensorFlow: Tworzenie sieci neuronowej i nauka podstaw uczenia maszynowego
Sztuczna inteligencja: Filozofia i myślenie maszynowe
Chcesz zrozumieć filozofię sztucznej inteligencji? Dowiedz się więcej o myśleniu maszynowym i różnicach w inteligencji! Przeczytaj artykuł!
Dowiedz się więcej