
Spis treści:
- Skąd pochodzą modele open source?
- Jak rozwijają się modele open source?
- Zalety i wady programów LLM typu open source?
- Jakie są rodzaje programów LLM typu open source?
- Główne rodzaje licencji typu open source?
- Jak znaleźć najlepszy program LLM?
- Przykłady popularnych modeli open source?
- Co jeszcze przeczytałeś?

Ucz się za darmo: „Sieci neuronowe. Kurs praktyczny”
Dowiedz się więcejKilka lat temu wprowadzenie na rynek nowego modelu języka open source wywołało spore poruszenie w społeczności IT. Dziś jednak proces ten stał się powszechny. Co miesiąc opracowywane są dziesiątki nowych modeli open source, a ich liczba sięga setek rocznie. Otwarte modele językowe stale ewoluują, wprowadzając nowe możliwości i poprawiając jakość przetwarzania języka naturalnego.
Aby ułatwić nawigację po różnorodnych dostępnych sieciach neuronowych, przygotowaliśmy szczegółowy przewodnik prezentujący aktualne modele open source. Ten zasób pomoże Ci szybko znaleźć odpowiednie narzędzia i technologie z dziedziny sztucznej inteligencji.
Optymalizacja tekstu pod kątem SEO wymaga nie tylko zmiany struktury, ale także skupienia się na słowach kluczowych i frazach, które mogą przyciągnąć odbiorców docelowych. Treść powinna być informacyjna, trafna i łatwa do zrozumienia.
Poniżej znajduje się poprawiony tekst:
Treść jest ważną częścią każdej treści, ponieważ pomaga użytkownikom szybko poruszać się po materiale. Prawidłowo sformatowany tekst o przejrzystej i logicznej treści poprawia doświadczenia użytkownika i przyczynia się do wyższych pozycji w wyszukiwarkach. Użycie słów kluczowych w nagłówkach i podtytułach nie tylko ułatwia nawigację, ale także czyni tekst bardziej przystępnym dla wyszukiwarek. Co więcej, trafność i unikalność treści odgrywają kluczową rolę w przyciąganiu i utrzymywaniu czytelników. Tworzenie wysokiej jakości treści o przejrzystej treści pomaga budować zaufanie do zasobu i zwiększa jego autorytet w oczach użytkowników i wyszukiwarek.
W ten sposób treść nie tylko porządkuje informacje, ale staje się również podstawą skutecznej strategii SEO.
- Skąd pochodzą modele open source?
- Jak się rozwijają?
- Jakie są ich zalety i wady?
- Jakie są rodzaje otwartych programów LLM?
- Na jakich licencjach open source są publikowane?
- Jak zidentyfikować najlepsze programy LLM?
- Na jakie popularne modele open source warto zwrócić uwagę?
- Co jeszcze warto przeczytać o otwartych i zastrzeżonych programach LLM?
Skąd pochodzą modele otwarte?
Istnieje wiele sieci neuronowych open source. Większość z nich nie jest jednak niezależnymi projektami, lecz powstaje w oparciu o kilka dużych modeli językowych (LLM), znanych jako modele fundamentalne. Te modele bazowe stanowią podstawę do opracowywania nowych rozwiązań z zakresu sztucznej inteligencji i uczenia maszynowego, umożliwiając badaczom i programistom tworzenie bardziej wyspecjalizowanych aplikacji i narzędzi.
Tworzenie i trenowanie modeli AI wymaga znacznych nakładów finansowych i potężnej mocy obliczeniowej. Dlatego prace te są dostępne przede wszystkim dla dużych zespołów badawczych i firm IT, takich jak Google i OpenAI. Przykładowo, trenowanie modelu GPT-3 kosztowało programistów prawie 5 milionów dolarów. Wysoki koszt trenowania takich modeli wynika z konieczności przetwarzania dużych wolumenów danych i korzystania z nowoczesnych technologii, co sprawia, że proces ten jest nieosiągalny dla wszystkich organizacji.
Model bazowy to sztuczna sieć neuronowa trenowana na dużej ilości danych. Można ją dostosować do rozwiązywania różnorodnych problemów, co czyni ją wszechstronnym narzędziem w uczeniu maszynowym. Dostrojenie modelu bazowego może poprawić jego wydajność i dokładność w określonych zadaniach, takich jak przetwarzanie języka naturalnego, rozpoznawanie obrazów i inne aplikacje. Wykorzystanie modeli bazowych otwiera nowe możliwości rozwoju inteligentnych systemów i poprawy jakości analiz.
Po zakończeniu prac rozwojowych nowy model może zostać udostępniony na licencji zastrzeżonej lub open source. Dzięki otwartej licencji inne firmy i niezależni programiści mają możliwość udoskonalania i dostosowywania modelu do rozwiązywania konkretnych problemów. Sprzyja to innowacjom i poprawia jakość produktu, ponieważ społeczność może wnosić ulepszenia i optymalizacje. Otwarte licencje ułatwiają również szersze rozpowszechnianie technologii i ich integrację z różnymi rozwiązaniami.
Korzystanie z open source'owych modeli LLM nie wymaga znacznych nakładów finansowych ani mocy obliczeniowej. Dlatego startupy często wybierają takie rozwiązania. Zmodyfikowane wersje modeli utworzonych z kodu źródłowego są powszechnie nazywane forkami (od angielskiego słowa fork). Umożliwia to deweloperom dostosowywanie technologii do swoich potrzeb, optymalizując je pod kątem konkretnych zadań i zwiększając wydajność.
Popularne modele bazowe stanowiące podstawę otwartych modeli LLM to:
- LLaMA i LLaMA 2 firmy Zuckerberg, ten drugi opracowany wspólnie z firmą Microsoft.
- BLOOM (duży, otwarty, wielojęzyczny model naukowy o otwartym dostępie) z projektu BigScience, stworzony przy udziale Hugging Face.
- GPT-2, opublikowany przez OpenAI kilka lat temu, gdy firma planowała rozwijać wyłącznie rozwiązania typu open source.
- Falcon to najnowsze osiągnięcie Instytutu Innowacji Technologicznych (TII) z Abu Zabi (ZEA).
- Rodzina modeli T5 firmy Google.
Nowoczesne modele LLM można przedstawić w formie drzewa genealogicznego, które ilustruje ich ewolucję i wzajemne powiązania. Te modele językowe, oparte na głębokich sieciach neuronowych, ewoluują z roku na rok, prezentując coraz bardziej złożone architektury i udoskonalone algorytmy. Od pierwszych prostych modeli po dzisiejsze, potężne systemy, takie jak GPT i BERT, można prześledzić, jak każda nowa wersja bazowała na wcześniejszych osiągnięciach, integrując nowe metody przetwarzania i uczenia języka naturalnego. Ewolucja modeli LLM nie tylko wzbogaca ich funkcjonalność, ale także rozszerza ich zastosowanie w różnych dziedzinach, takich jak automatyczne tłumaczenie, tworzenie treści i analiza danych. Zrozumienie genealogii modeli LLM jest zatem istotne dla badaczy i programistów, którzy chcą wykorzystać ich możliwości w swoich projektach.
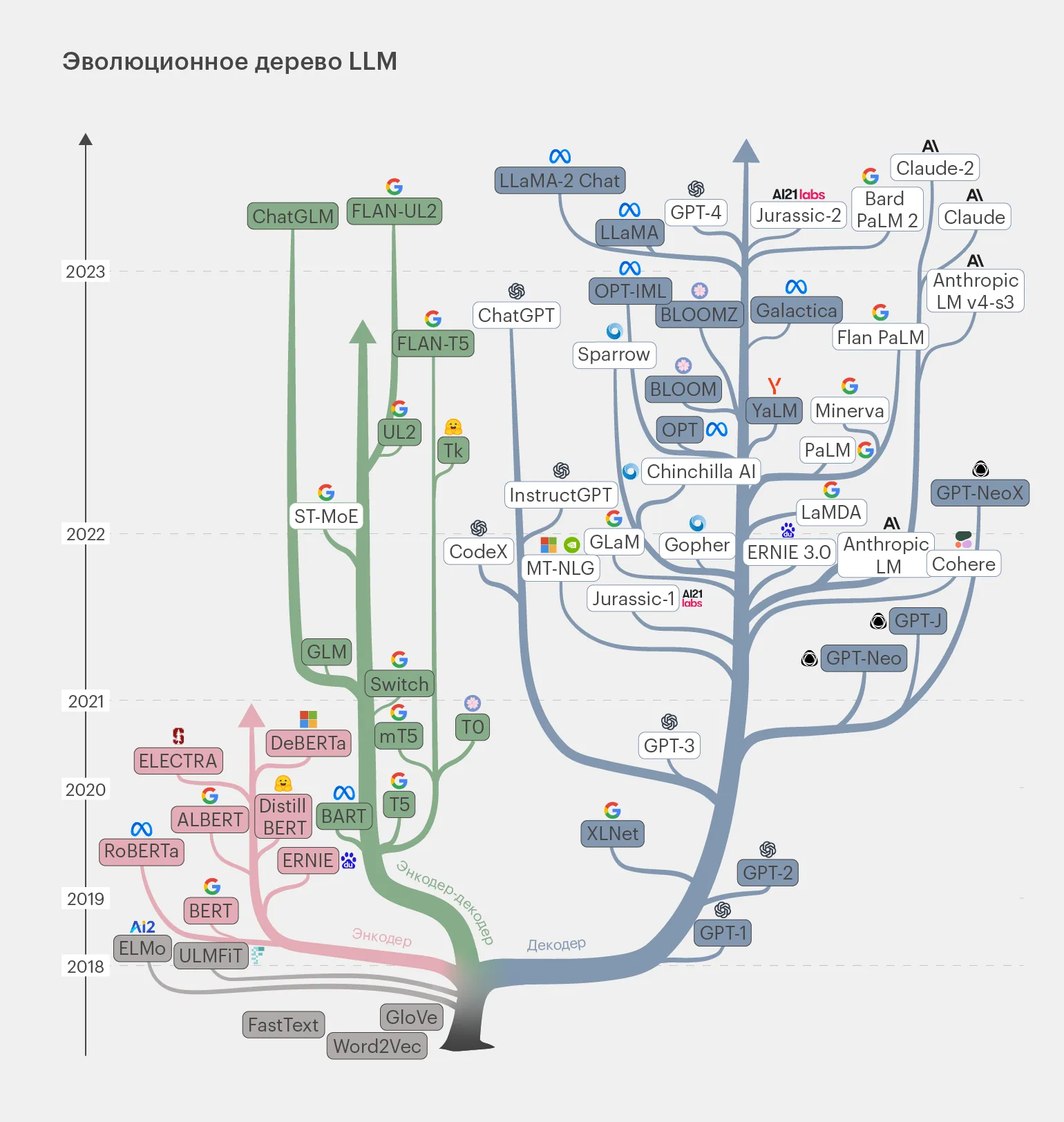
Ten diagram koncentruje się na modelach przedstawionych w wypełnionych prostokątach. Modele te reprezentują rozwiązania open source, które omówimy dzisiaj. Rozważymy ich główne cechy i ewolucję, jaka nastąpi do 2023 roku.
Jak ewoluują modele open source
Modele LLM z otwartą licencją charakteryzują się tymi samymi problemami, co zastrzeżone sieci neuronowe, w tym częstymi halucynacjami, ograniczeniami długości okna kontekstowego i koniecznością przetwarzania informacji z różnych modalności. Te aspekty determinują podobieństwo kierunków ich rozwoju. Zatem zarówno modele otwarte, jak i zamknięte stoją przed podobnymi wyzwaniami, co podkreśla wagę dalszych badań i ulepszeń w tym obszarze.
Zmniejszanie halucynacji w modelach językowych. Modele językowe, takie jak LLM, mogą generować błędne dane, które wydają się prawdopodobne. Błędy te nazywane są halucynacjami. Do tej pory nie udało się całkowicie wyeliminować takich niedokładności w odpowiedziach sieci neuronowych. Chociaż algorytmy i metody treningowe są stale udoskonalane, minimalizacja halucynacji pozostaje palącym problemem dla programistów.
Liderem w walce z halucynacjami jest zamknięty model GPT-4, który charakteryzuje się wskaźnikiem błędu na poziomie zaledwie 3% przypadków. Jednak pod względem dokładności jest on bliski otwartemu modelowi LLaMA 2 70B, którego wydajność jest porównywalna ze znanym, zastrzeżonym modelem Gemini firmy Google DeepMind. Oba rozwiązania reprezentują najnowocześniejsze technologie w dziedzinie przetwarzania języka naturalnego, a ich wydajność czyni je cennymi narzędziami dla wielu zastosowań.
Zwiększenie długości okna kontekstowego jest istotnym czynnikiem wpływającym na wydajność i jakość odpowiedzi modeli językowych (LLM). Im większą objętość tekstu może przetworzyć model, tym bardziej świadome i precyzyjne odpowiedzi może on generować. Dzieje się tak, ponieważ rozszerzenie okna kontekstowego znacząco zwiększa ilość danych dostępnych do analizy, co z kolei poprawia zrozumienie kontekstu i zmniejsza prawdopodobieństwo wystąpienia błędów. Dlatego zwiększenie długości okna kontekstowego jest kluczowym krokiem w poprawie wydajności LLM i ulepszeniu doświadczenia użytkownika.
Modele o zamkniętym kodzie źródłowym GPT-4 i Claude 100K wykazują zdolność do jednoczesnego przetwarzania ponad 100 000 tokenów, co znacznie rozszerza ich funkcjonalność. Jednocześnie aktywnie rozwijają się sieci neuronowe o otwartym kodzie źródłowym, dążąc do osiągnięcia podobnych rezultatów w dziedzinie przetwarzania informacji. Te osiągnięcia otwierają nowe horyzonty dla zastosowań sztucznej inteligencji w różnych dziedzinach, w tym w analizie danych, tworzeniu treści i automatyzacji procesów. Zainteresowanie udoskonalaniem modeli open source rośnie, napędzając globalny postęp w rozwoju sieci neuronowych.
Podstawowy model Mistral 7B przetwarza 8000 tokenów, a jego nowoczesny fork, Nous-Yarn-Mistral-7B-128k, firmy Nous Research, znacznie rozszerza jego możliwości, obsługując okno kontekstowe do 128 000 tokenów. To znaczące ulepszenie pozwala modelom na efektywniejsze przetwarzanie i analizę dużych wolumenów danych tekstowych, otwierając nowe horyzonty w przetwarzaniu języka naturalnego i uczeniu maszynowym.
Przetwarzanie danych z różnych modalności. Nowoczesne sieci neuronowe mogą skutecznie przetwarzać nie tylko dane tekstowe, ale także obrazy, wideo i audio. Funkcjonalność ta została już zaimplementowana w kilku programach LLM o otwartym kodzie źródłowym, rozszerzając ich zastosowanie w różnych dziedzinach, takich jak widzenie komputerowe, rozpoznawanie mowy i analiza multimediów. Dzięki podejściu wielodomenowemu sieci neuronowe mogą analizować i integrować dane z różnych źródeł, co znacząco zwiększa ich funkcjonalność i dokładność.
- model języka wizualnego Nous-Hermes-2-Vision-Alpha;
- multimodalna sieć neuronowa Qwen-VL chińskiej firmy Alibaba Cloud;
- multimodalna wersja LLaMA o nazwie LLaVA-13B.

Obniżenie kosztów rozwoju LLM. Jednym z głównych problemów związanych z sieciami neuronowymi jest wysoki koszt tworzenia podstawowych modeli. Jednak dzięki temu, że niektóre z nich są dostępne na otwartych licencjach, koszty dalszego szkolenia i wdrożenia są znacznie obniżone. Na przykład udoskonalenie i uruchomienie modeli open source Alpaca i Vicuna-13B, opartych na LLaMA, kosztowało deweloperów odpowiednio tylko 600 i 300 dolarów. Dzięki temu sieci neuronowe stają się bardziej dostępne dla programistów i promują ich szersze zastosowanie w różnych dziedzinach.
Jednym ze skutecznych sposobów na obniżenie kosztów jest wykorzystanie sieci neuronowych do generowania syntetycznych danych treningowych i oceny wydajności nowych modeli. Metoda ta znana jest jako RLAIF (Reinforcement Learning with AI Feedback) i pozwala na optymalizację procesu treningowego, poprawę wyników i skrócenie czasu rozwoju. Wykorzystanie RLAIF zwiększa wydajność i zmniejsza ryzyko błędów, co czyni ją ważnym narzędziem w nowoczesnych technologiach uczenia maszynowego.
Uruchamianie modeli językowych na sprzęcie niskiej klasy staje się coraz bardziej dostępne. Większość modeli językowych o otwartym kodzie źródłowym ma mniej parametrów niż ich odpowiedniki o zamkniętym kodzie źródłowym. Pozwala to na efektywne wykorzystanie takich modeli na urządzeniach o ograniczonych zasobach, w tym na komputerach domowych. Użytkownicy mogą łatwo integrować i testować te sieci neuronowe, otwierając nowe możliwości rozwoju i eksperymentowania w dziedzinie przetwarzania języka naturalnego.
Mistral 7B ma znacznie mniejszą liczbę parametrów w porównaniu z GPT-3.5, stanowiąc zaledwie 25% jego objętości. W rezultacie wymagania obliczeniowe są niższe: Mistral 7B wymaga około 187 razy mniej mocy obliczeniowej niż GPT-4 i dziewięć razy mniej niż GPT-3.5. Dzięki temu Mistral 7B staje się bardziej dostępnym rozwiązaniem dla deweloperów i firm, które chcą wykorzystać potencjał sztucznej inteligencji bez ponoszenia znacznych kosztów obliczeniowych.

Jest pracownikiem naukowym w grupie semantyki obliczeniowej w Instytucie Sztucznej Inteligencji AIRI i prowadzi badania w dziedzinie Przetwarzanie języka i rozwój metod umożliwiających maszynom rozumienie i interpretację znaczenia tekstów. Nacisk kładziony jest na tworzenie algorytmów, które analizują relacje semantyczne między słowami i frazami, co jest kluczowym aspektem w rozwoju inteligentnych systemów. Praca w tej grupie przyczynia się do wdrażania zaawansowanych technologii w różnych dziedzinach, takich jak automatyczne tłumaczenie, systemy pytań i odpowiedzi oraz analiza danych.
Modele open source dają firmom możliwość korzystania z LLM z minimalnymi ograniczeniami. Otwarte rozwiązania pozwalają firmom w pełni kontrolować sposób przetwarzania danych użytkowników, dostosowywać je do konkretnych wymagań i znacznie zmniejszać ryzyko dzięki wykorzystaniu własnej infrastruktury. To sprawia, że technologie open source są atrakcyjne dla przedsiębiorstw dążących do poprawy bezpieczeństwa i efektywności zarządzania danymi.
Pojawienie się modeli open source było istotnym czynnikiem podnoszącym poziom kompetencji w środowisku akademickim w dziedzinie pracy z modelami językowymi (LLM). Dziś nikogo nie dziwi chatbot taki jak ChatGPT, którego może uruchomić na laptopie entuzjasta. Jeszcze dwa lata temu wydawało się to niemożliwe. Postęp technologiczny i dostępność narzędzi otwierają nowe możliwości badań i rozwoju w dziedzinie sztucznej inteligencji, pobudzając zainteresowanie i aktywność zarówno specjalistów, jak i amatorów.
Ulepszanie istniejących i rozwijanie nowych architektur sieci neuronowych to palący problem w dziedzinie sztucznej inteligencji. Jednym z kluczowych problemów związanych z modelami językowymi dużej skali (LLM) są ograniczenia architektury transformatorowej, co prowadzi do licznych niedociągnięć w ich działaniu. Rozwiązań tego problemu oczekuje się od startupów, które opracowują modele open source i aktywnie eksperymentują z ich wewnętrzną strukturą. Innowacje w architekturach sieci neuronowych mogą znacząco poprawić wydajność i efektywność modeli, co z kolei rozszerzy ich zastosowanie w różnych dziedzinach.
Architektura Mixture of Experts (MoE) może być rozwiązaniem pozwalającym na poprawę wydajności modeli takich jak GPT-4. Architektura ta obejmuje osiem eksperckich sieci neuronowych, z których każda specjalizuje się w określonych zadaniach. Opublikowany model Mixtral 8x7B, разработанная французской компанией Mistral AI, демонстрирует в шесть раз большую скорость генерации ответов по сравнению сисходной моделью LLaMA 2 70B. Использование MoE позволяет значительно оптимизировать производительность i adadapтивность нейросетей, что особенно важно для создания высококачественного контента i улучшения пользовательского опыта.
Powiadomienie мультиагентных систем на основе языковых моделей (LLM) представляет собой инновационный подход к улучшению качества работы нейросетей. В отличие от изменения архитектуры, этот метод фокусируется на создании систем, состоящих из множества независимых агентов, которые способны взаимодействовать i договариваться друг с другом. Такой подход позволяет эффективно решать сложные задачи пользователей, используя коллективный интеллект нескольких нейросетей. Мультиагентные способны адаптироваться к различным сценариям, что делает их особенно полезными w сфере обработки естественного языка и других областях, где требуется гибкость и динамичность в решении задач.
Идеальными кандидатами для использования в таких системах являются открытые LLM, которые не требуют значительных вычислительных ресурсов. Ten сегодняшний день уже существуют проекты, такие как AutoGPT, GPT-Engineer, LangChain i GPTeam, которые успешно реализуют эти технологии. Открытые LLM обеспечивают доступность i гибкость в разработке, позволяя пользователям эффективно использовать возможности искусственного интеллекта без необходимости в дорогостоящем оборудовании.
Создание больших языковых моделей (LLM) для языков, отличных от английского, представляет собой сложную задачу. Нейросети чаще всего используют английский язык, так как именно на нём основана значительная часть обучающих данных. Это приводит к тому, что другие языки, на которых говорят десятки и сотни миллионов людей, оказываются в менее выгодном положении. Обучение моделей для работы с такими языками требует значительных усилий по поиску и созданию качественных датасетов, что в свою очередь подразумевает дополнительные ресурсы и время. Таким образом, развитие LLM для различных языков становится важной задачей, которая потребует внимания инвестиций для достижения равноправия в обработке языковых данных.
Pomimo potęgi nowoczesnych sieci neuronowych, takich jak GPT-4, obsługują one zaledwie kilkaset języków spośród ponad 7000 istniejących. Eksperci uważają, że rozwiązanie tego problemu można znaleźć w modelach językowych o otwartym kodzie źródłowym (LLM). Rozwój dostępnych i wielojęzycznych modeli LLM może znacznie rozszerzyć możliwości językowe, umożliwiając większej liczbie osób dostęp do zaawansowanych technologii przetwarzania języka naturalnego.
W 2023 roku zaprezentowano nowy model Jais, opracowany w Zjednoczonych Emiratach Arabskich, który umożliwia komunikację w języku arabskim. Zapowiedziano również wariant LLaMA dostosowany do języka portugalskiego. W Rosji Yandex i Sber wydały sieci neuronowe YaLM 100B i ruGPT-3.5 13B, skoncentrowane na języku rosyjskim. Rozwój ten podkreśla aktywny rozwój technologii sztucznej inteligencji i ich adaptację do różnych języków, co otwiera nowe możliwości dla użytkowników na całym świecie.
Prace nad rzadkimi językami trwają. W 2023 roku ruszył projekt Massively Multilingual Speech (MMS), którego celem jest stworzenie zbiorów danych dla 1100 języków, które dotychczas nie były objęte badaniami. Celem tego projektu jest rozszerzenie możliwości przetwarzania mowy i udoskonalenie technologii automatycznego rozpoznawania mowy dla wielu języków, co znacznie zwiększy dostępność informacji i usług dla rodzimych użytkowników tych języków.

Czytaj także:
Tygrys i Smok: chińskie projekty i perspektywy w dziedzinie generatywnej AI
Chiny Chiny aktywnie rozwijają technologie generatywnej sztucznej inteligencji, dążąc do zajęcia pozycji lidera w tej dynamicznie rozwijającej się branży. Synergia potężnych zasobów obliczeniowych i bogatych zasobów danych pozwala temu krajowi opracowywać innowacyjne rozwiązania, które zmieniają podejście do sztucznej inteligencji.
Chińskie firmy i instytucje badawcze pracują nad tworzeniem zaawansowanych modeli zdolnych do generowania tekstu, obrazów, a nawet muzyki. Te zmiany otwierają nowe horyzonty dla różnych sektorów gospodarki, w tym edukacji, opieki zdrowotnej i rozrywki.
Wsparcie rządu i inwestycje w startupy odgrywają kluczową rolę w przyspieszaniu rozwoju branży. Chińskie przedsiębiorstwa aktywnie współpracują z partnerami międzynarodowymi, ułatwiając wymianę wiedzy i technologii.
Perspektywy rozwoju generatywnej sztucznej inteligencji w Chinach wydają się obiecujące, od tworzenia spersonalizowanych rozwiązań dla użytkowników po automatyzację procesów biznesowych. Oczekuje się, że kraj ten w nadchodzących latach wniesie znaczący wkład w globalny ekosystem sztucznej inteligencji.

Pracownik naukowy w grupie semantyki obliczeniowej w Instytucie Sztucznej Inteligencji AIRI zajmuje się badaniem i opracowywaniem algorytmów, które umożliwiają komputerom rozumienie i przetwarzanie języka naturalnego. Głównym celem niniejszej pracy jest stworzenie modeli zdolnych do analizy semantycznego znaczenia tekstu, co otwiera nowe horyzonty dla zastosowań sztucznej inteligencji w różnych dziedzinach, takich jak automatyczne tłumaczenie, przetwarzanie danych i interakcja człowiek-komputer. Specjaliści z tej dziedziny aktywnie uczestniczą w projektach interdyscyplinarnych, które przyczyniają się do rozwoju technologii i poprawy jakości interakcji z systemami informatycznymi. Modele open source otwierają nowe możliwości dla biznesu, umożliwiając efektywne wykorzystanie LLM bez istotnych ograniczeń. Rozwiązania open source zapewniają firmom pełną kontrolę nad przetwarzaniem danych użytkowników, ułatwiając ich dostosowanie do specyficznych potrzeb biznesowych. To nie tylko zwiększa elastyczność, ale także znacząco zmniejsza ryzyko, ponieważ firmy mogą korzystać z własnej infrastruktury do przetwarzania i przechowywania informacji. Tym samym technologie open source stają się ważnym narzędziem zapewniającym bezpieczeństwo i optymalizującym zarządzanie danymi we współczesnym biznesie. Pojawienie się modeli open source znacząco podniosło poziom kompetencji środowiska akademickiego w zakresie pracy z dużymi modelami językowymi (LLM). Dziś chatboty podobne do ChatGPT, tworzone przez pasjonatów na zwykłych laptopach, nie są już niczym zaskakującym. To osiągnięcie, które zaledwie dwa lata temu uznano za science fiction, świadczy o szybkim postępie technologii i dostępności narzędzi dla programistów i badaczy.
Zalety i wady programów LLM typu open source
Firmy wybierają sieci neuronowe typu open source ze względu na ich liczne zalety w porównaniu z modelami zastrzeżonymi. Po pierwsze, rozwiązania typu open source zapewniają większą elastyczność i możliwość personalizacji, umożliwiając im dostosowanie modeli do konkretnych potrzeb biznesowych. Po drugie, pomagają obniżyć koszty, ponieważ nie wymagają licencji ani dodatkowych opłat za użytkowanie. Po trzecie, dostępność kodu źródłowego pozwala programistom wprowadzać zmiany i ulepszenia, a także łatwo integrować sieci neuronowe z istniejącymi systemami. Co więcej, społeczność programistów aktywnie wspiera takie projekty, ułatwiając szybkie rozwiązywanie problemów i dzielenie się wiedzą. Wreszcie, sieci neuronowe typu open source zapewniają wysoki poziom przejrzystości, umożliwiając firmom lepszą kontrolę procesów i wyników swoich modeli. Dlatego wybór sieci neuronowych typu open source staje się coraz bardziej uzasadniony dla organizacji poszukujących innowacji i optymalizacji procesów.
- Bezpieczeństwo danych i prywatność. Modele LLM typu open source można wdrażać we własnej infrastrukturze bez wysyłania informacji na serwery zewnętrzne. Daje to użytkownikom pełną kontrolę nad danymi przetwarzanymi przez sieć neuronową.
- Oszczędność kosztów. Modele LLM typu open source można używać bez opłat abonamentowych ani regularnych płatności w ramach umów deweloperskich. Dzięki temu są popularne wśród startupów i firm o ograniczonym budżecie.
- Mniejsze uzależnienie od dostawców usług IT. Użytkownicy mogą wybrać najodpowiedniejszą opcję sieci neuronowej spośród setek modeli LLM typu open source. W ten sposób firma nie jest związana z jednym dostawcą rozwiązań AI i może wybierać najlepsze modele, a nawet je łączyć.
- Przejrzystość stosowanych modeli LLM. Modele typu open source można analizować wewnętrznie, aby zrozumieć, jak dokładnie przetwarzają dane. Pomaga to identyfikować i zapobiegać wysyłaniu informacji na serwery zewnętrzne.
- Projekty typu open source są wspierane przez zespoły deweloperów i ekspertów. Dzięki temu wszelkie błędy i problemy są szybko rozwiązywane, a dokumentacja szczegółowo opisuje niuanse korzystania z sieci neuronowej. Jest to typowe dla większości modeli open source, ale istnieją pewne godne uwagi wyjątki.
- Niekonwencjonalne rozwiązania i podejścia. Otwarte modele LLM umożliwiają eksperymentowanie ze sztuczną inteligencją, opierając się na nowych, fundamentalnych modelach. Nawet małe startupy mogą kreatywnie przekształcać takie sieci neuronowe i wykorzystywać je jako podstawę własnych, unikalnych rozwiązań.

Dyrektor generalny Avatar Machine, twórca psychologa-czatbota Sabina Ai i współautor FractalGPT Projekt, jest specjalistą w dziedzinie technologii i sztucznej inteligencji. Pod jego kierownictwem firma odniosła znaczący sukces w tworzeniu innowacyjnych rozwiązań wspierających i rozwijających inteligencję emocjonalną z wykorzystaniem nowoczesnych narzędzi cyfrowych. Chatbot Sabina Ai oferuje użytkownikom dostęp do wsparcia psychologicznego i konsultacji z wykorzystaniem zaawansowanych algorytmów przetwarzania języka naturalnego. Projekt FractalGPT z kolei demonstruje możliwości głębokiego uczenia się i generowania tekstu, otwierając nowe horyzonty w dziedzinie interakcji człowiek-maszyna.
Powszechne pojawianie się i upowszechnianie dużych, otwartych modeli językowych jest napędzane globalnym trendem zwiększania produktywności i obniżania kosztów studiów magisterskich (LLM). Konsumenci obecnie dążą do porzucenia zamkniętych, zastrzeżonych rozwiązań, które tworzą zależność od zagranicznych dostawców i niestabilność polityczną. Czynniki te powodują odejście od rozwiązań renomowanych zagranicznych gigantów IT, takich jak OpenAI. Otwarte modele językowe zapewniają użytkownikom większą elastyczność i kontrolę, co czyni je coraz bardziej atrakcyjnymi w obliczu współczesnych wyzwań.
Otwarte modele LLM mają swoje wady. Po pierwsze, takie modele mogą mieć ograniczenia jakości danych. Często są one trenowane na mniej zróżnicowanych i niskiej jakości zestawach danych, co może negatywnie wpłynąć na ich wydajność i dokładność. Po drugie, brak komercyjnego wsparcia może stwarzać problemy z aktualizacjami i poprawkami błędów, potencjalnie wprowadzając luki w zabezpieczeniach. Ponadto, otwarte modele LLM mogą być mniej zoptymalizowane i dostosowane niż rozwiązania zastrzeżone, co może ograniczać ich zastosowanie w określonych zadaniach. Wreszcie, korzystanie z otwartych modeli LLM wymaga umiejętności technicznych w zakresie konfiguracji i integracji, co może stanowić barierę dla niektórych użytkowników. Wdrożenie i konserwacja mogą wymagać więcej czasu i wiedzy technicznej niż modele zastrzeżone, które zazwyczaj są gotowe do użycia od razu. Programy opracowane przez mało znane zespoły mogą być trenowane na niekompletnych lub niskiej jakości danych. Zmniejsza to dokładność odpowiedzi sieci neuronowych i zwiększa częstotliwość występowania halucynacji.

Prezes A-Ya Expert LLC, firmy specjalizującej się w rozwoju systemów sztucznej inteligencji. Koncentrujemy się na tworzeniu innowacyjnych rozwiązań AI, które pomagają firmom optymalizować procesy i zwiększać wydajność. Nasz zespół ekspertów opracowuje najnowocześniejsze technologie, które ułatwiają automatyzację i analizę danych. Dążymy do bycia liderem w branży sztucznej inteligencji (AI), oferując naszym klientom unikalne i wysokiej jakości produkty.
Programy LLM typu open source muszą być otwarte nie tylko pod względem kodu źródłowego modelu, ale także pod względem danych, na których są trenowane. Jest to kluczowe, ponieważ problem „zatruwania danych” (data poisoning) pozostaje aktualny. Ważne jest zapewnienie czystości i przejrzystości danych, aby zagwarantować niezawodność i bezpieczeństwo modeli. Współczesne rozwiązania będą koncentrować się na rozwiązywaniu tych problemów, co zwiększy zaufanie użytkowników i poprawi jakość wyników uzyskiwanych z programów LLM.
Inżynierowie, naukowcy i organizacje rządowe stają przed pytaniami o zaufanie do danych podczas korzystania z rozwiązań opartych na modelach AI typu open source. Aby pomyślnie zintegrować modele open source z odpowiednim segmentem rynku, niezbędna jest otwartość i wysokiej jakości zbiory danych, na których trenowane są sieci neuronowe. Zwiększy to poziom zaufania do technologii i zapewni ich szersze zastosowanie w różnych branżach.

Czytaj również:
Otwarte i wolne oprogramowanie (Open Source) przyciąga uwagę ze względu na swoją dostępność i przejrzystość. Jednak za jego zaletami kryją się pewne zagrożenia. Jednym z głównych zagrożeń jest możliwość wprowadzenia złośliwego kodu. Ponieważ kod źródłowy jest publicznie dostępny, atakujący mogą wykorzystać luki w zabezpieczeniach, aby tworzyć exploity. Co więcej, brak scentralizowanego wsparcia może prowadzić do problemów z bezpieczeństwem, ponieważ aktualizacje i poprawki nie zawsze są publikowane w odpowiednim czasie.
Należy również wziąć pod uwagę kwestie zgodności i zależności. Korzystanie z oprogramowania open source może powodować konflikty między różnymi bibliotekami, komplikując proces rozwoju i wsparcia. Brak profesjonalnego wsparcia może pozbawić użytkowników niezbędnych zasobów do rozwiązywania problemów, co negatywnie wpłynie na procesy biznesowe.
Należy również wziąć pod uwagę aspekty prawne. Licencje open source mogą zawierać warunki ograniczające jego wykorzystanie w celach komercyjnych, co może prowadzić do konsekwencji prawnych dla organizacji.
Dlatego, pomimo atrakcyjności oprogramowania open source i wolnego oprogramowania, ważne jest, aby dokładnie ocenić związane z nim ryzyko i podjąć działania w celu jego zminimalizowania. Upewnij się, że rozumiesz warunki licencji, zadbaj o bezpieczeństwo swojego kodu i przygotuj się na potencjalne problemy z pomocą techniczną.

Prezes Avatar Machine, twórca psychologicznego chatbota Sabina Ai i współautor projektu FractalGPT. Wiodący ekspert w dziedzinie sztucznej inteligencji i automatyzacji, z doświadczeniem w tworzeniu innowacyjnych rozwiązań wspierających zdrowie psychiczne. Strategicznie koncentruje się na rozwijaniu technologii, które pomagają poprawić jakość życia użytkowników poprzez dostępne i skuteczne narzędzia. Powszechne wdrażanie i dystrybucja rozbudowanych modeli językowych typu open source jest napędzana globalnym trendem zwiększania produktywności i obniżania kosztów studiów magisterskich (LLM). Współcześni konsumenci dążą do porzucenia zamkniętych, zastrzeżonych rozwiązań, ponieważ prowadzą one do uzależnienia od zagranicznych dostawców i czynników politycznych. Te okoliczności skłaniają użytkowników do poszukiwania alternatyw dla popularnych rozwiązań oferowanych przez międzynarodowych gigantów IT, takich jak OpenAI. Otwarte modele językowe pomagają unikać ryzyka związanego z zagrożeniami zewnętrznymi i zapewniają większą elastyczność w korzystaniu z technologii przetwarzania języka naturalnego.

Prezes zarządu A-Ya Expert LLC, firmy specjalizującej się w rozwoju systemów sztucznej inteligencji, odgrywa kluczową rolę w tworzeniu innowacyjnych rozwiązań w tej dziedzinie. Pod jego kierownictwem firma rozwija najnowocześniejsze technologie, które pomagają optymalizować procesy biznesowe i zwiększać efektywność różnych organizacji. Systemy sztucznej inteligencji firmy są wykorzystywane w różnych branżach, w tym w finansach, opiece zdrowotnej i produkcji, co potwierdza ich wszechstronność i zapotrzebowanie rynku. Programy nauczania języka angielskiego (LLM) oparte na otwartym kodzie źródłowym muszą być otwarte, zarówno pod względem kodu źródłowego, jak i danych, na których są szkolone. Jest to szczególnie ważne w świetle narastającego problemu „zatruwania danych” (data poisoning). Obecnie nacisk przesuwa się na zapewnienie czystości i przejrzystości danych, co jest kluczem do zwiększenia zaufania do modeli. Otwartość w tych obszarach nie tylko poprawia jakość szkolenia, ale także zmniejsza ryzyko związane z wykorzystaniem nieprawdziwych informacji. Inżynierowie, naukowcy i agencje rządowe stoją przed istotnymi pytaniami dotyczącymi zaufania do danych podczas korzystania z rozwiązań opartych na modelach sztucznej inteligencji opartych na otwartym kodzie źródłowym. Для того чтобы опенсорсные модели смогли занять свою нишу на рынке, необходимы высокая степень открытости i качественные датасеты, на которых происходит обучение нейросетей. Это позволит повысить уровень доверия к результатам работы таких моделей i обеспечит их конкурентоспособность в различных сферах.
Kakimi открытые LLM
Modele z открытым кодом clasсифицируются по нескольким параметрам, включая степень обученности, размер и поддержку различных языков. Рассмотрим каждый из этих аспектов более подробно.
Разработчики часто публикуют в открытом доступе только предобученные версии своих нейронных сетей, известные как «претрейны». К примеру, специалисты компании «Сбер» сделали доступной отечественную модель ruGPT-3.5, а также аналогично поступил Марк Цукерберг с исходной моделью LLaMA. Такие решения позволяют исследователям и работчикам использовать уже готовые решения для дальнейших экспериментов и доработок, что способствует развитию технологий искусственного интеллекта и расширяет возможности их применения в различных сферах.
Языковые модели перед публикацией проходят длительный процесс обучения на обширных объемах неразмеченных текстовых dzień. Этот процесс требует значительных вычислительных ресурсов и финансовых вложений. В результате нейронные сети формируют общее понимание языка, что позволяет iм эфективно обрабатывать i генерировать текст.
Использование «претрейн» для решения конкретных задач может быть затруднительным. Он в основном предназначен для генерации продолжений текстовых последовательностей, которые ввводит пользователь. К примеру, система может легко завершить фразу, начинающуюся с определения: «Машинное обучение — это… —. Однако для более сложных задач требуется дополнительная настройка i адаптация.
Если пользователь попытается начать диалог с nie jest to możliwe неуместные или бессмысленные ответы вместо предоставления полезной inформации. Это может привести к недопониманию i снижению доверия к технологии, что подчеркивает важность дальнейшего развития i обучения нейросетей для повышения качества взаимодействия с пользователями.
Popularność nowoczesnych modeli językowych wynika nie z wstępnego trenowania, lecz z modeli bazowych, które przeszły dodatkowe dostrajanie. Te modele LLM zazwyczaj zawierają w swoich nazwach słowo „Chat”, jeśli sieć została dostrojona do obsługi konwersacji, lub „Instruct”, jeśli może wykonywać instrukcje przy użyciu metody podobnej do metody RLHF używanej do trenowania ChatGPT. Dostrajanie znacząco poprawia komfort użytkowania i rozszerza funkcjonalność modeli, czyniąc je bardziej odpowiednimi dla różnych zastosowań związanych z przetwarzaniem języka naturalnego.
Istnieją również bardziej wyspecjalizowane opcje dostrajania. Na przykład model MPT-7B jest dostępny w wersji StoryWriter, która koncentruje się na tworzeniu fikcyjnych historii z długimi kontekstami. Warto również zwrócić uwagę na liczne modele językowe generujące kod programu. Słowo „Code” często pojawia się w nazwach takich sieci neuronowych, jak w przypadku StableCode, CodeGeneX i innych podobnych rozwiązań. Modele te wykazują wysoką skuteczność w automatyzacji programowania i upraszczaniu tworzenia oprogramowania.
Zgodnie z tym kryterium modele LLM (Large Language Models) można podzielić na trzy główne kategorie:
- angielskojęzyczne;
- obsługujące jeden język lokalny, taki jak rosyjski;
- wielojęzyczne, które mogą obsługiwać jednocześnie kilka języków innych niż angielski.
W przypadku korzystania z sieci neuronowych w Rosji ważne jest rozważenie obsługi języka rosyjskiego, ponieważ znacznie poprawia to interakcję użytkownika z technologią. Jednak językiem podstawowym większości modeli pozostaje angielski, co może stwarzać pewne trudności dla użytkowników rosyjskojęzycznych. Pomyślna integracja sieci neuronowych na rynku rosyjskim wymaga opracowania i adaptacji modeli zdolnych do efektywnej współpracy z językiem rosyjskim i uwzględniających specyfikę kulturową.
Wynika to z faktu, że największa ilość danych niezbędnych do trenowania sieci neuronowych jest dostępna w tym języku. Inne języki wymagają dodatkowego trenowania i modyfikacji architektonicznych, aby osiągnąć porównywalne wyniki. Ponieważ różnorodność danych ma kluczowe znaczenie dla efektywnego trenowania modeli, korzystanie z tego języka zapewnia znaczną przewagę w rozwoju i optymalizacji sieci neuronowych.
Prawie wszystkie modele open source są w stanie przetwarzać język rosyjski. Jednak głównym problemem jest to, że większość popularnych modeli językowych (LLM) została opracowana z myślą o języku angielskim, a przynajmniej alfabecie łacińskim. Oznacza to, że teksty w cyrylicy zajmują więcej miejsca na tokeny, co z kolei znacznie ogranicza kontekst wykorzystania modelu. Optymalizacja tokenizatorów cyrylicy mogłaby poprawić jakość przetwarzania języka rosyjskiego w modelach open source.
Michaił Salnikow to nazwisko kojarzone z profesjonalizmem i wysokim poziomem wiedzy specjalistycznej w swojej dziedzinie. Dzięki wieloletniemu doświadczeniu Michaił stał się uznanym specjalistą, który potrafi rozwiązywać złożone problemy i znajdować skuteczne rozwiązania. Jego podejście opiera się na dogłębnej analizie i dbałości o szczegóły, co pozwala mu osiągać doskonałe rezultaty. Michaił aktywnie dzieli się swoją wiedzą i doświadczeniem, pomagając innym rozwijać się i odnosić sukcesy w ich dziedzinie.
Współczesne trendy w sieciach neuronowych pokazują, że rozmiar modelu nie zawsze decyduje o jego skuteczności. Sieci neuronowe typu open source, nawet te o niewielkich rozmiarach, są w stanie dostarczać wyniki porównywalne z dużymi systemami zastrzeżonymi. Wybierając model językowy (LLM), należy zwrócić uwagę na równowagę między rozmiarem a wydajnością – model musi być wystarczająco kompaktowy, aby rozwiązywać określone problemy, zapewniając jednocześnie niezbędną funkcjonalność i jakość.
Każdy model można oceniać za pomocą regularnie aktualizowanych metryk jakości, zwanych benchmarkami. Na podstawie tych metryk wszystkie modele LLM (Large Language Models) można podzielić na dwie główne kategorie.
- Modele, które wykazują wyniki bliskie pewnej „jakości granicznej”. Z reguły ChatGPT (GPT-3.5-Turbo) jest uważany za model bazowy.
- Modele, które nie spełniają stosunku ceny do wydajności. Są to albo zbyt duże modele LLM, których koszt jest poza skalą, albo bardzo małe, zawierające mniej niż 7 miliardów parametrów. Te ostatnie zazwyczaj mają luki w wydajności, które są wykrywane za pomocą indywidualnych testów porównawczych związanych ze zrozumieniem języka.
Viktor Nosko to uznany specjalista w swojej dziedzinie. Posiada bogate doświadczenie i głęboką wiedzę, co pozwala mu skutecznie rozwiązywać złożone problemy. Jego podejście do pracy zawsze opiera się na wysokich standardach jakości i dbałości o szczegóły. Victor aktywnie dzieli się swoją wiedzą z kolegami i młodymi specjalistami, przyczyniając się do rozwoju społeczności zawodowej. Jego chęć ciągłego uczenia się i samodoskonalenia czyni go cennym nabytkiem dla każdego zespołu. Dzięki swojemu zaangażowaniu i wysokim kwalifikacjom, Victor Nosko ugruntował swoją pozycję jako wiarygodny partner i ekspert w swojej dziedzinie.
Drugim ważnym parametrem związanym z rozmiarem modelu jest typ LLM: pełny lub skwantyzowany. Kwantowanie sieci neuronowej znacznie zmniejsza wymagania dotyczące mocy obliczeniowej i pamięci RAM. Warto jednak zauważyć, że zmniejsza to dokładność modelu języka. Wybór między wersją pełną a skwantowaną zależy od problemów do rozwiązania i dostępnych zasobów. Pełne LLM zapewniają wyższą dokładność i jakość przetwarzania, podczas gdy wersje skwantyzowane są odpowiednie dla Aplikacje o ograniczonych zasobach obliczeniowych.
Oczywiście, chętnie pomogę w edycji tekstu. Proszę o dostarczenie samego tekstu do przerobienia.
Koszty hostingu modeli są często obniżane poprzez kwantyzację. Pozwala to na uruchomienie modelu nawet na standardowych domowych kartach graficznych, takich jak NVIDIA GTX lub RTX 3070–3090. Warto jednak zauważyć, że takie podejście może obniżyć wydajność modelu o 5–15% w porównaniu z wersją oryginalną. W niektórych przypadkach takie obniżenie jakości jest akceptowalne dla użytkowników.
Victor Nosko to nazwisko, które stało się symbolem profesjonalizmu i jakości w swojej dziedzinie. Ugruntował swoją pozycję eksperta oferującego unikalne rozwiązania i pomysły. Dzięki swojemu doświadczeniu i umiejętnościom, Victor Nosko przyciąga uwagę nie tylko klientów, ale także kolegów z branży.
W swojej pracy Victor Nosko stawia na innowacyjność i efektywność, co pozwala mu osiągać wysokie rezultaty. Kluczowym aspektem jego podejścia jest ciągła chęć samorozwoju i uczenia się, co czyni go poszukiwanym Specjalista.
Viktor Nosko aktywnie dzieli się swoją wiedzą i doświadczeniem, prowadząc kursy mistrzowskie i seminaria. Pozwala mu to nie tylko umacniać swoją pozycję na rynku, ale także budować społeczność profesjonalistów gotowych do wymiany pomysłów i doświadczeń.
Sukces Viktora Nosko wynika nie tylko z jego wysokiego profesjonalizmu, ale także ze zdolności do znajdowania wspólnego języka z klientami, co przyczynia się do długoterminowych partnerstw. Jego praca koncentruje się na wynikach i zadowoleniu klienta, co jest kluczem do sukcesu w konkurencyjnym środowisku.
Viktor Nosko to nie tylko nazwisko, ale marka kojarzona z niezawodnością i jakością.
Główne rodzaje licencji open source
Nie wszystkie modele open source są równie dostępne. Stopień otwartości zależy od licencji wybranej przez twórcę. Niektóre licencje zapewniają pełną swobodę użytkowania i modyfikacji, podczas gdy inne mogą nakładać ograniczenia. Ważne jest, aby uważnie zapoznać się z warunkami licencji, aby zrozumieć możliwości i ograniczenia konkretnego modelu open source.
Częściowo otwarte modele mają szereg istotnych ograniczeń w ich użytkowaniu. Na przykład twórcy LLaMA 2 wymagają od użytkowników akceptacji umowy z obszerną listą warunków i zakazów przed pobraniem. Jednym z głównych wymogów jest zakaz używania sieci neuronowej w projektach z ponad 700 milionami użytkowników miesięcznie. Ponadto wyników LLaMA 2 nie można używać do trenowania innych modeli językowych, z wyjątkiem samego LLaMA i jego pochodnych. Podkreśla to wagę przestrzegania warunków licencji podczas pracy z sieciami neuronowymi.
Większość dużych modeli językowych (LLM) jest rozpowszechniana na podstawie licencji wolnego oprogramowania. Główne z nich obejmują następujące rodzaje licencji:
- Apache 2.0 pozwala na korzystanie z modeli w dowolnym celu, modyfikowanie ich i dystrybucję zgodnie z warunkami licencji, bez płacenia tantiem twórcy. Zdecydowana większość modeli LLM o otwartym kodzie źródłowym została stworzona na podstawie tej licencji: T5, Mistral 7B i inne.
- Licencja MIT została opracowana przez Massachusetts Institute of Technology (MIT). Jest w dużej mierze identyczna z Apache 2.0, ale pozwala na ponowne wykorzystanie kodu open source w oprogramowaniu zastrzeżonym. Na przykład ta licencja jest używana dla modelu Phi-2 firmy Microsoft.
- Open RAIL-M v1 jest wspierany przez społeczność BigCode, stworzoną przez Hugging Face. Licencja zapewnia bezpłatny dostęp do modeli, możliwość modyfikacji ich kodu źródłowego oraz udostępnianie modeli LLM i ich wariantów. Zawiera szereg ograniczeń związanych z zakazem używania ich w działaniach nieetycznych lub niezgodnych z prawem. Model BLOOM jest rozpowszechniany na podstawie tej licencji.
- CC BY-SA 4.0 jest wspierana przez międzynarodową organizację non-profit Creative Commons. Zezwala ona na kopiowanie i rozpowszechnianie modeli LLM, ich modyfikowanie i uzupełnianie w dowolnym celu, w tym do użytku komercyjnego. Jednak w tym ostatnim przypadku nowe modele powinny być rozpowszechniane na tej samej licencji co oryginał. Model MPT-7B-Chat jest licencjonowany na podstawie tej licencji. Licencja.
- BSD-3-Clause. Licencja wolnego oprogramowania z minimalnymi ograniczeniami dotyczącymi użytkowania i dystrybucji sieci neuronowych. Zezwala na nieograniczone kopiowanie w dowolnym celu, pod warunkiem dołączenia zastrzeżenia dotyczącego praw autorskich i zastrzeżenia gwarancyjnego. Rzadko używana. Udało nam się znaleźć jeden popularny LLM z podobną licencją – CodeT5+.

Aby poprawić widoczność w wyszukiwarkach, ważne jest zoptymalizowanie tekstu przy jednoczesnym zachowaniu jego głównej treści. Zachęcamy do zapoznania się z aktualnymi informacjami na interesujący Cię temat. Zadbaj o to, aby Twoje treści były angażujące i przydatne dla czytelników, co pomoże zwiększyć ruch na Twojej stronie.
Ciągłe aktualizowanie i uzupełnianie materiałów pomoże utrzymać zainteresowanie odbiorców i poprawić pozycję w wynikach wyszukiwania. Nie zapomnij śledzić aktualnych trendów i zmian w tematyce, aby być na bieżąco.
Przeczytaj również:
Licencje BSD i MIT: kluczowe różnice i zastosowania
Licencje BSD i MIT to popularne licencje open source stosowane w tworzeniu oprogramowania. Obie licencje pozwalają użytkownikom na swobodne używanie, modyfikowanie i dystrybucję oprogramowania. Istnieją jednak pewne kluczowe różnice między nimi, które mogą wpłynąć na wybór licencji dla Twojego projektu.
Licencja BSD, pierwotnie opracowana na Uniwersytecie Kalifornijskim Berkeley występuje w kilku wariantach, w tym w wersji 2-klauzulowej i 3-klauzulowej. Podstawowe postanowienia obu wersji pozwalają użytkownikom na dowolne korzystanie z kodu, pod warunkiem zachowania informacji o prawach autorskich i zastrzeżenia. Wersja 3-klauzulowa dodaje wymóg, że nazwa projektu nie może być używana w celach reklamowych bez zezwolenia.
Z kolei licencja MIT jest bardziej zwięzła i prostsza. Zezwala na dowolne wykorzystanie kodu, pod warunkiem zachowania informacji o prawach autorskich i licencji na kopiach oprogramowania. MIT jest powszechnie uważana za łatwiejszą w zrozumieniu i użyciu, co czyni ją popularną wśród programistów.
Obie licencje są szeroko stosowane w różnych projektach, od małych bibliotek po duże pakiety oprogramowania. Na przykład projekty na GitHubie często wybierają MIT ze względu na prostotę, podczas gdy większe projekty, takie jak FreeBSD i OpenBSD, korzystają z BSD dla większej elastyczności.
Wybór między licencją BSD a MIT zależy od specyfiki projektu i jego wymagań licencyjnych. Podejmując decyzję, ważne jest, aby wziąć pod uwagę zarówno kwestie prawne, jak i prawne. rozważania i preferencje społeczności programistów.
Jak znaleźć najlepszego LLM
Aby określić najskuteczniejszy model języka open source (LLM), eksperci opracowali wirtualne areny testowe znane jako rankingi. Na tych platformach modele językowe konkurują ze sobą, co pozwala im ocenić swoją wydajność oraz zidentyfikować mocne i słabe strony.
Na platformach dedykowanych ocenie sieci neuronowych każdy model jest analizowany pod kątem szeregu wskaźników jakości, zwanych benchmarkami. Należy pamiętać, że nie ma idealnego modelu języka, który wyróżniałby się we wszystkich wskaźnikach. Model może dobrze wypadać w jednym kryterium, ale słabo w innych. Podkreśla to potrzebę holistycznego podejścia do oceny sieci neuronowych, aby w pełni zrozumieć ich możliwości i ograniczenia.
Wybierając LLM, ważne jest, aby skupić się na wskaźnikach, które najlepiej odpowiadają danemu zadaniu. Większość aren testowych oferuje Przyjazny dla użytkownika interfejs, który pozwala sortować dostępne modele według interesujących Cię parametrów. Pozwala to szybko znaleźć optymalne rozwiązania i efektywnie wykorzystać możliwości każdego modelu.
Zalecamy zapoznanie się z kilkoma popularnymi rankingami. Pomogą Ci one wybrać najodpowiedniejszą opcję i ocenić pozycje różnych uczestników w danej dziedzinie. Rankingi to doskonałe narzędzie do analizy i porównywania, pozwalające zidentyfikować najlepszych w Twoim segmencie. Wybór odpowiedniego rankingu może znacząco poprawić Twoją strategię i zwiększyć Twoją efektywność.
- Otwarty ranking LLM. Platforma firmy Hugging Face zaprojektowana do śledzenia, klasyfikowania i automatycznej oceny najnowszych programów LLM i chatbotów prezentowanych na stronie internetowej o tej samej nazwie. Wykorzystuje oryginalny system oceny modeli językowych EleutherAI, oparty na obliczeniach siedmiu benchmarków.
- Tabela Chatbot Arena. Kolejna otwarta platforma do oceny LLM na stronie internetowej Hugging Face. Działa w oparciu o model crowdsourcingu. Zebrała ponad 200 000 opinii od prawdziwych użytkowników, umożliwiając ocenę modeli językowych za pomocą systemu rankingowego ELO, podobnego do do rankingu używanego do obliczania umiejętności szachistów.
Główną koncepcją Chatbot Arena Leaderboard jest parami porównywane jakości odpowiedzi modeli, przeprowadzane przez ludzkich asesorów z wykorzystaniem rankingu ELO. Istnieją tak zwane metody „oszukiwania”, które pozwalają modelom osiągać wysokie wyniki w testach porównawczych, które nie zawsze odzwierciedlają ich rzeczywistą jakość. W tej sytuacji ręczna ocena oparta na prostym porównaniu pomaga częściowo rozwiązać ten problem, zapewniając dokładniejsze przedstawienie rzeczywistych możliwości modeli.
Viktor Nosko to nazwisko kojarzone z różnymi osiągnięciami i projektami. Jest znany ze swojej wiedzy specjalistycznej w określonych dziedzinach, co czyni go poszukiwanym specjalistą. Viktor aktywnie angażuje się w życie publiczne i dzieli się swoją wiedzą za pośrednictwem różnych platform. Jego praca i inicjatywy mają na celu rozwój i wspieranie młodych ludzi, co podkreśla jego zaangażowanie w poprawę społeczeństwa. Co ważne, wkład Viktora Nosko w jego zawód i całe społeczeństwo ma pozytywny wpływ i inspiruje innych do działania.
- AlpacaEval Leaderboard. Automatyczny system oceny modeli językowych należących do Instruuj klasę. Opierając się na metodologii AlpacaFarm, która testuje zdolność LLM do przestrzegania ogólnych instrukcji użytkownika, wykorzystuje sztuczną inteligencję opartą na modelu GPT-4 jako „sędziego” i źródło odpowiedzi referencyjnych.
- Chatbot Arena. Разработка LMSYS Org (Large Model Systems Organisation) i Калифорнийского университета в Беркли, создавшей модель Vicuna-13B. Важно, что niepublikowany od maja 2023 r.
- Tabela liderów modeli Big Code. Система оценки LLM, предназначенных для генерации программного kodada. Очередная разработка Przytulanie Twarzy. Лидерборд не обновлялся с ноября 2023 года, поэтому может содержать неактуальные данные.
Платформа Przytulanie twarzy занимает лидирующие позиции в области машинного обучения и обработки естественного языка. Она предлагает обширный набор бенчмарков, известных как The Big Benchmarks Collection. Благодаря этому пользователи могут легко настраивать рейтинги и выбирать оптимальные модели для решения конкретных задач, таких как написание koda. Hugging Face предоставляет удобные instrumenty, которые упрощают процесс выбора и тестирования моделей, что делает ее идеальным решением для разработчиков i исследователей в сфере ИИ.
В данной области активны не только специализированные компании. Rozwiń open-source-сообщества также стремятся разработать универсальную систему оценки, которая объединит лучшие черты всех существующих liderbordow. Примером такого подхода является проект LLM-Leaderboard, инициированный Людвигом Штумппом из Германии. Этот проект нацелен на создание единой платформы для оценки и сравнения языковых моделей, что может значительно облегчить исследователям i разработчикам выбор оптимальных решений для их задач.
Открытые модели машинного обучения показывают результаты, близкие к проприетарным в большинстве задач. Например, в задачах, связанных с ответами на вопросы или упрощением текстов, пользователи могут не zapamiętaj wejdź na stronę internetową LLaMA 2 70B i ChatGPT. Кроме того, разрыв в производительности между закрытыми и открытыми моделями продолжает уменьшаться, что делает открытые решения все более конкурентоспособными.
Михаил Сальников — профессионал в своей области, обладающий значительным опытом и знаниями. Его работа охватывает множество аспектов, что делает его ценным специалистом. Michał постоянно совершенствует свои навыки, следит за новыми тенденциями и активно применяет их в своей praktyka. Его подход к делу основан на внимании к деталям и стремлении к высокому качеству. Сальников также делится своими знаниями с коллегами, что способствует развитию команды и повышению общей эфективности работы.
Михаил Сальников — это имя, которое ассоциируется с надежностью и профессионализмом. Его достижения в сфере деятельности вдохновляют многих, а его опыт служит примером для więcej.

Чтение является важной частью нашей жизни, предоставляя нам возможность расширять горизонты, получать новые знания и развивать мышление. Это увлечение не только развлекает, но и обогащает, открывая доступ к различным культурам и идеям. Регулярное чтение помогает улучшить словарный запас, развить аналитические навыки i повысить уровень концентрации. Независимо от того, предпочитаете ли вы художественную литературу, научные статьи или деловые книги, каждый жанр предлагает уникальные преимущества. Найдите время для чтения каждый день, и вы заметите положительные изменения в своем восприятии мира и уровне интеллекта.
Sieci neuronowe zyskują coraz większą popularność i znaczenie w różnych dziedzinach życia i biznesu. W tym kontekście przedstawiamy 30 zaawansowanych sieci neuronowych, które mogą być przydatne w rozwiązywaniu różnorodnych problemów. Narzędzia te obejmują szeroki zakres zastosowań, od przetwarzania języka naturalnego po generowanie obrazów i analizę danych. Wykorzystanie sieci neuronowych może znacznie poprawić wydajność pracy, zautomatyzować procesy i uzyskać cenne informacje z dużych wolumenów danych. Zapoznaj się z naszymi rekomendacjami, aby wybrać odpowiednią sieć neuronową do swoich potrzeb i zoptymalizować przepływy pracy.
Przykłady popularnych modeli open source
Większość programów LLM typu open source opiera się na kilku kluczowych modelach. Przyjrzyjmy się najważniejszym.
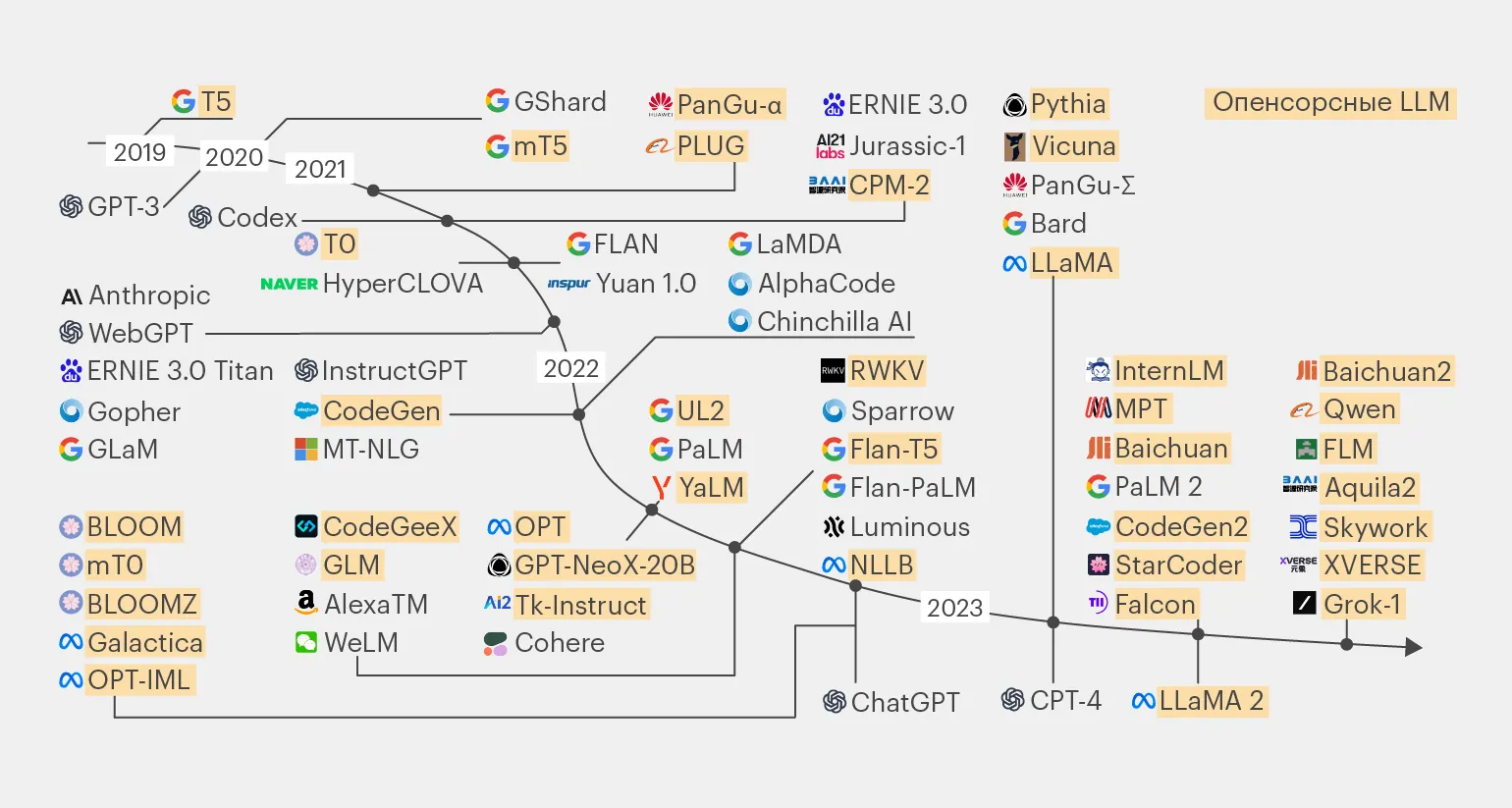
Model LLaMA został wprowadzony w lutym 2023 roku i oferuje różne warianty z 7, 13, 33 i 65 miliardami parametrów. Cechą charakterystyczną dwóch pierwszych wersji jest możliwość uruchomienia ich na jednym procesorze GPU, co wywołało prawdziwą sensację w momencie premiery. Te cechy sprawiają, że model LLaMA jest dostępny dla szerokiego grona użytkowników i programistów, przyczyniając się do jego popularności w dziedzinie sztucznej inteligencji i przetwarzania języka naturalnego.
W lipcu 2023 roku zaprezentowano zaktualizowaną wersję LLaMA 2, stworzoną we współpracy z firmą Microsoft. Ten model językowy (LLM) oferuje trzy warianty z 7, 13 i 70 miliardami parametrów. Ulepszenia w LLaMA 2 mają na celu zwiększenie wydajności przetwarzania i generowania tekstu, czyniąc go odpowiednim do różnorodnych zastosowań, od automatyzacji po tworzenie treści.
Model LLaMA został wykorzystany jako podstawa dla wersji open source OpenLLaMA, która stała się podstawą licznych projektów. Projekty te mają na celu rozwój modelu poprzez eksperymenty architektoniczne, a także różne metody dostrajania i trenowania. OpenLLaMA daje badaczom i programistom możliwość ulepszania i dostosowywania modelu do konkretnych zadań, rozszerzając tym samym jego zastosowanie w wielu dziedzinach.
LLaMA 2 70B to model warunkowo open source, dostępny z kodem źródłowym i wagami. Jego komercyjne wykorzystanie jest jednak ograniczone: gdy liczba użytkowników przekroczy 700 milionów miesięcznie, staje się nieakceptowalny. Model ten zajmuje znaczącą pozycję na rynku i jest jednym z najbardziej znanych po rozwiązaniach o zamkniętym kodzie źródłowym, takich jak ChatGPT i Claude 2. LLaMA 2 70B charakteryzuje się wysoką wydajnością i jakością, co czyni go atrakcyjnym dla programistów i badaczy zajmujących się sztuczną inteligencją.
Michaił Salnikow jest znaną postacią w swojej dziedzinie. Jego osiągnięcia i doświadczenie budzą zainteresowanie i szacunek. Salnikow aktywnie angażuje się w swoją pracę zawodową, wnosząc znaczący wkład w rozwój branży. Jego podejście do pracy i innowacyjne pomysły inspirują wielu współpracowników. Michaił Salnikow to nazwisko kojarzone z jakością i niezawodnością, a jego praca nadal wpływa na liczne projekty i inicjatywy.
W 2023 roku model LLaMA przyniósł znaczący przełom w powszechnym stosowaniu sieci neuronowych typu open source. Na jego podstawie opracowano dziesiątki nowych modeli, w tym Mistral, Zephyr, Alpaca, Phi-2, Qwen, Yi i wiele innych. Te osiągnięcia przyczyniają się do rozwoju zastosowań sieci neuronowych w różnych dziedzinach, w tym w przetwarzaniu języka naturalnego, sztucznej inteligencji i uczeniu maszynowym. Co ważne, otwartoźródłowy charakter tych modeli pozwala badaczom i programistom wykorzystywać i ulepszać te technologie, napędzając szybki postęp w dziedzinie sztucznej inteligencji.
Victor Nosko jest znaną postacią w swojej dziedzinie. Ugruntował swoją pozycję eksperta o dogłębnej wiedzy i doświadczeniu. W swojej pracy koncentruje się na bieżących problemach i oferuje skuteczne rozwiązania. Jego podejście jest unikalne i innowacyjne, co pozwala mu wyróżniać się na tle innych specjalistów. Dzięki swoim osiągnięciom Victor Nosko stał się autorytetem i źródłem inspiracji dla wielu. Jego praca i pomysły przyczyniają się do rozwoju i doskonalenia praktyk w tej dziedzinie, co czyni jego wkład nieocenionym.
W tym artykule zbieramy opinie ekspertów na temat popularnych modeli językowych o otwartym kodzie źródłowym (LLM) z rodziny LLaMA. Wyróżnili najciekawsze modele, przedstawiając krótką charakterystykę i cechy każdego z nich.
Sprawdź poniższe otwarte modele LLM (modele językowe) – mogą być przydatne w różnych zadaniach. Modele te zapewniają dostęp do najnowocześniejszych technologii przetwarzania języka naturalnego i mogą być skutecznie wykorzystywane w badaniach naukowych, rozwoju oprogramowania i tworzeniu treści. Otwarte modele LLM oferują użytkownikom możliwość dostosowywania i adaptowania modeli do swoich potrzeb, dzięki czemu stają się wszechstronnymi narzędziami do rozwiązywania różnorodnych problemów w dziedzinie sztucznej inteligencji i uczenia maszynowego. Rozważ integrację tych modeli ze swoimi projektami, aby poprawić ich wydajność i jakość.
- Vicuna-13B od LMSYS Org to jeden z pierwszych modeli obsługujących język rosyjski, który jednocześnie wykazuje dobre wyniki w innych testach porównawczych.
- Mistral to model francuskiego startupu o tej samej nazwie, który we wszystkich testach porównawczych przewyższa LLaMA 2 13B. Na koniec września 2023 r. był to najlepszy model LLM z rozmiarem 7 miliardów parametrów.
- Zephyr-7B to wersja Mistrala dopracowana za pomocą technologii Direct Preference Optimization (DPO). W rankingu AlpacaEval ma 90,6% wskaźnik wygranych w porównaniu z innymi sieciami neuronowymi.
- OpenChat to biblioteka modeli językowych o otwartym kodzie źródłowym. Szacuje się, że osiągnie jakość ChatGPT (wersja z marca 2023 r.), a także przewyższy chatbota Elona Muska Grok. Obsługuje język rosyjski. OpenChat 7B bazuje na Mistral 7B, ale w przeciwieństwie do niego zdaje słynny „test banana”, który polega na zadaniu LLM pytania: „Jestem w kuchni, kładę talerz na bananie. Potem zabieram talerz do sypialni. Gdzie teraz jest banan?”.
- Xwin-LM-70B-V0.1 to model oparty na LLaMA 2. Według twórców, jest to pierwszy model, który przewyższył GPT-4 w benchmarku AlpacaEval. Jego rozmiar jest jednak dość duży – 70 miliardów parametrów”.
Viktor Nosko to nazwisko zasługujące na uwagę w swojej dziedzinie. Jest znany ze swoich osiągnięć i wkładu w rozwój różnorodnych projektów. Dzięki swojemu doświadczeniu i profesjonalnemu podejściu Viktor Nosko stał się autorytetem w swojej dziedzinie. Jego praca odzwierciedla wysokie standardy jakości i zaangażowanie w ciągłe doskonalenie. Jeśli szukasz niezawodnego eksperta lub partnera, Viktor Nosko to ktoś, na kim możesz polegać.
Mistral 7B przyciąga uwagę, ponieważ przy zaledwie 7 miliardach parametrów osiąga lepsze wyniki w porównaniu z LLaMA 2, który ma ich 13 miliardów. Dzięki temu model ten jest dostępny do użycia na większości nowoczesnych laptopów, co rozszerza jego zastosowanie w różnorodnych zadaniach.
Polecam zapoznać się z modelem Dolly amerykańskiej firmy Databricks. Chociaż nie jest on powiązany z LLaMA i opiera się na rodzinie EleutherAI Pythia, jego otwartość oferuje unikalne możliwości. Model jest w pełni dostępny do wykorzystania w różnych celach, co stanowi jego główną zaletę. To sprawia, że Dolly jest atrakcyjnym wyborem dla programistów i badaczy, którzy chcą zastosować zaawansowane narzędzia w swoich projektach.
Michaił Salnikow to nazwisko, które zyskało popularność w niektórych kręgach dzięki swoim osiągnięciom i wkładowi w swoją dziedzinę. Dał się poznać jako profesjonalista z głęboką wiedzą i doświadczeniem. Salnikov aktywnie angażuje się w różnorodne projekty, co pozwala mu utrzymać się w czołówce w swojej dziedzinie. Jego praca charakteryzuje się wysoką jakością i innowacyjnym podejściem, co czyni go cenionym specjalistą. Warto zauważyć, że Michaił nieustannie dąży do samodoskonalenia i poznawania nowych trendów, co pozwala mu być konkurencyjnym na rynku. Salnikov jest przykładem tego, jak sukces można osiągnąć dzięki wytrwałości i profesjonalizmowi.
Rosja aktywnie rozwija własne modele uczenia się języków (LLM), specjalnie dostosowane do pracy z językiem rosyjskim. Technologie te mają na celu poprawę interakcji z użytkownikiem i poprawę jakości przetwarzania rosyjskich informacji tekstowych. Stworzenie takich modeli umożliwi znaczny postęp w dziedzinie sztucznej inteligencji i uczenia maszynowego, a także wsparcie lokalnych potrzeb i specyfiki językowej.
Wśród rosyjskich osiągnięć w dziedzinie sztucznej inteligencji warto zwrócić uwagę na ruGPT-3.5, który stanowi podstawę GigaChat Sberbanku. Publicznie dostępna jest tylko wstępnie wytrenowana wersja, co oznacza, że do osiągnięcia optymalnych rezultatów niezbędne jest niezależne, dalsze szkolenie.
Rozwój Sberbanku konkuruje z modelem YaGPT 2 firmy Yandex, który nie jest jeszcze powszechnie dostępny. W 2022 roku Yandex wprowadził poprzednika tego modelu, YaLM 100B, wydanego na licencji Apache 2.0. Model ten przyciągnął już uwagę specjalistów i badaczy sztucznej inteligencji ze względu na swoje imponujące cechy i możliwości. Konkurencja między Sberem a Yandexem w dziedzinie technologii AI uwydatnia rosnące zainteresowanie rozwojem innowacyjnych rozwiązań, które mogą transformować różne obszary biznesu i życia codziennego. Wśród rosyjskich programów LLM wyróżnia się model Saiga 2, opracowany przez inżyniera uczenia maszynowego Ilję Gusiewa. Model ten jest pozycjonowany jako „rosyjski chatbot”, oparty na architekturach LLaMA 2 i Mistral. Saiga 2 oferuje unikalne możliwości interakcji z użytkownikami, zapewniając wysoką jakość odpowiedzi i adaptację do różnorodnych żądań. Zainteresowanie takimi modelami rośnie, ponieważ przyczyniają się one do rozwoju technologii przetwarzania języka naturalnego w Rosji.
Głównym krajowym osiągnięciem w dziedzinie sztucznej inteligencji jest ruGPT-3.5, który został wykorzystany do stworzenia GigaChat. To rozwiązanie jest obecnie jednym z najlepszych w przypadku treści rosyjskojęzycznych. Warto również zwrócić uwagę na YandexGPT, który również charakteryzuje się wysoką wydajnością w pracy z językiem rosyjskim. Jednak twórcy nie udostępnili jeszcze otwartego dostępu do modelu YandexGPT, co ogranicza jego zastosowanie.
Michaił Salnikow to nazwisko, które budzi zainteresowanie w różnych dziedzinach. Warto zauważyć, że Michaił Salnikow może być kojarzony z wieloma dziedzinami, w tym ze sztuką, nauką i biznesem. Jeśli szukasz informacji o Michaile Salnikowie, powinieneś wziąć pod uwagę jego osiągnięcia i wkład w wybraną dziedzinę. Nazwisko to może być kojarzone z kreatywnością, innowacyjnością lub przedsiębiorczością. W zależności od kontekstu, Michaił Salnikow jest postacią, która pozostawiła po sobie zauważalny ślad.
W dziedzinie dużych modeli językowych (LLM) istotny obszar poświęcony jest trenowaniu sieci neuronowych do pisania kodu oprogramowania. Obecnie istnieje kilka popularnych modeli open source, które są aktywnie wykorzystywane w tym celu. Modele te pozwalają programistom automatyzować proces kodowania, zwiększając produktywność i skracając czas tworzenia oprogramowania. Optymalizacja oprogramowania z wykorzystaniem sieci neuronowych otwiera nowe horyzonty w programowaniu, czyniąc je bardziej przystępnym i wydajnym.
- StableCode firmy StabilityAI, twórców Stable Diffusion. Umożliwia programowanie w językach Python, Java, Go, JavaScript, C i C++.
- StarCoder to zestaw modeli z 15,5 miliarda parametrów trenowanych w ponad 80 językach programowania.
- SantaCoder to seria modeli o rozmiarze 1,1 miliarda parametrów zbudowana na bazie GPT-2. Wyszkolony do generowania kodu w Pythonie, Javie i JavaScript.
- CodeGeeX i CodeGeeX2 od chińskich specjalistów. Pierwsza wersja sieci neuronowej z 13 miliardami parametrów została wyszkolona w 20 językach programowania, druga – o rozmiarze 6 miliardów – może kodować w 100 językach. Wśród nich są Python, Java, C++, C#, JavaScript, PHP i Go. Można ją podłączyć jako wtyczkę do popularnych środowisk IDE: Visual Studio Code, IntelliJ IDEA i Android Studio.
- Replit Code to model językowy o rozmiarze 2,7 miliarda parametrów, wyszkolony pod kątem uzupełniania kodu. Wyszkolony na zbiorach danych zawierających 20 języków, w tym Java, JavaScript, Python i PHP.
- CodeT5 i CodeT5+. Rodzina modeli amerykańskiej firmy Salesforce Research. Jak sama nazwa wskazuje, LLM opiera się na podstawowym otwartym modelu T5. Istnieją warianty z 220 milionami, 770 milionami, 2 miliardami, 6 miliardami i 16 miliardami parametrów. Umożliwiają kodowanie w Ruby, JavaScript, Pythonie, Javie, PHP, C, C++, C#.
- CodeGen2 i CodeGen2.5 to kolejna rodzina open-source'owych modeli LLM o standardowych rozmiarach 1, 3,7, 7 i 16 miliardów parametrów, pochodzących z tego samego badania Salesforce.
- DeciCoder 1B to skromny model z 1 miliardem parametrów, który potrafi uzupełniać fragmenty kodu programu sugerowane przez ludzi. Jest trenowany w Pythonie, Javie i JavaScript. Jednocześnie, według twórców, „zapewnia 3,5-krotny wzrost wydajności, zwiększoną dokładność w teście HumanEval i mniejsze zużycie pamięci w porównaniu z powszechnie używanymi modelami LLM do generowania kodu, takimi jak SantaCoder”.
- Code LLaMA to wersja LLaMA 2, która została przeszkolona do pracy z kodem programu. Posiada warianty dla 7, 13 i 34 miliardów parametrów. Obsługuje języki Python, C++, Java, PHP, C# i TypeScript.

Przeczytaj także:
Nowoczesne sieci neuronowe stają się niezbędnymi narzędziami dla programistów, pozwalając im znacznie przyspieszyć proces pisania kodu i poprawić jego jakość. W tym artykule przyjrzymy się siedmiu najpopularniejszym sieciom neuronowym, które mogą pomóc programistom w ich pracy. Wykorzystanie tych technologii nie tylko upraszcza rutynowe zadania, ale także pomaga ulepszać kod poprzez automatyczną weryfikację i optymalizację.
Dzięki sieciom neuronowym programiści mogą generować kod, naprawiać błędy i proponować lepsze rozwiązania dla różnych zadań. Narzędzia te umożliwiają analizę ogromnych ilości danych, umożliwiając im znalezienie optymalnych algorytmów i podejść. Integracja sieci neuronowych z procesem pracy pozwala programistom skupić się na bardziej kreatywnych aspektach programowania, pozostawiając rutynowe zadania sztucznej inteligencji.
Wykorzystując sieci neuronowe, programiści mogą nie tylko zwiększyć swoją produktywność, ale także poprawić jakość produktu końcowego. W rezultacie rozwój staje się bardziej efektywny, a finalne rozwiązania – bardziej niezawodne i optymalne. Sieci neuronowe otwierają przed programistami nowe horyzonty, pozwalając im osiągać lepsze rezultaty w krótszym czasie.
Co jeszcze warto przeczytać
Ten artykuł stanowi przegląd szerokiego tematu modeli języka typu open source. Jeśli chcesz zgłębić świat modeli języka typu open source i zastrzeżonych (LLM), zalecamy zapoznanie się z dwoma artykułami naukowymi opublikowanymi na stronie arxiv.org. Artykuły te dostarczają cennych danych i analiz, które pomogą Ci lepiej zrozumieć obecne trendy i technologie w dziedzinie modeli języka.
- Przegląd dużych modeli języka.
- Wykorzystanie potencjału programów LLM w praktyce: Przegląd ChatGPT i nie tylko.
Możesz śledzić najnowsze informacje ze świata programów LLM typu open source na platformie GitHub i w innych specjalistycznych zasobach. Regularne gromadzenie i aktualizacje pomogą Ci być na bieżąco z nowymi osiągnięciami i ulepszeniami w dziedzinie modeli językowych open source. Pozwoli Ci to nie tylko śledzić trendy, ale także uczestniczyć w społeczności, dzielić się doświadczeniami i otrzymywać aktualne informacje na temat zastosowań LLM.
- Lista programów LLM open source dostępnych do użytku komercyjnego.
- Kolekcja programów LLM open source i prawnie zastrzeżonych.
- Lista dużych modeli językowych.
- Kolekcja chińskich modeli open source.
- Krótki przewodnik po zestawach danych do dostrajania modeli.
Będziemy Cię informować o najważniejszych wydarzeniach w dziedzinie sztucznej inteligencji i wydarzeniach związanych ze społecznością open source na naszym kanale Telegram. Подписывайтесь, чтобы быть в курсе последних трендов и технологий в этих динамично развивающихся сферах.
Переделанный текст:
Изучите дополнительные материалы:
- 10 мифов о свободном ПО
- Wszystkie informacje: итоги 2023 года в сфере ИИ
- Что ждёт IT-специалистов w Nowym Roku 2024: прогнозы i пожелания от лучших нейросетей
Судом принято решение о запрете деятельности comпании Meta Platforms Inc. на территории Российской Федерации в отношении реализации социальных сетей Facebook i Instagram. To решение было принято на основе обвинений w осуществлении экстремистской деятельности.
