Spis treści:
- 1. Podstawowe koncepcje statystyki opisowej
- 2. Zrozumienie rozkładów danych
- 3. Próbkowanie: sztuka wyboru
- 4. Zrozumienie błędów w modelowaniu
- Czym jest wariancja i jej znaczenie w statystyce
- Zrozumienie wariancji: jak wpływa na analizę danych
- 6. Dylemat błędu systematycznego i wariancji w uczeniu maszynowym
- 7. Korelacja: zrozumienie i zastosowanie

Kurs Pythona: 4 projekty do Twojego portfolio
Dowiedz się więcej1. Podstawowe koncepcje statystyki opisowej
Statystyki opisowe są ważnym narzędziem w analizie danych, ponieważ zapewniają szczegółowy opis i podsumowanie cech zbiorów danych. W przeciwieństwie do statystyki predykcyjnej, głównym celem statystyki opisowej jest przedstawienie danych w przejrzystej i przystępnej formie. Pozwala to badaczom i analitykom lepiej zrozumieć strukturę i cechy danych oraz identyfikować wzorce i trendy. Statystyki opisowe obejmują takie miary, jak średnia, mediana, moda, wariancja i odchylenie standardowe, które pomagają scharakteryzować rozkład danych i jego cechy. Użycie statystyki opisowej to pierwszy krok w analizie, umożliwiający przygotowanie danych do dalszej eksploracji i interpretacji.
Główne wskaźniki stosowane w statystyce opisowej obejmują kluczowe miary tendencji centralnej. Miary te pozwalają podsumować dane i zidentyfikować ich główne cechy. Należą do nich średnia, mediana i moda, które pomagają analizować rozkład i zachowanie badanych danych. Prawidłowe użycie tych miar pozwala na dokładniejszą interpretację wyników i wyciąganie trafnych wniosków na podstawie informacji statystycznych.
- Średnia: Obliczana jako średnia arytmetyczna, która jest sumą wszystkich wartości podzieloną przez ich liczbę. Pozwala to uzyskać ogólny obraz danych.
- Mediana: Aby znaleźć medianę, należy posortować dane w kolejności rosnącej i znaleźć wartość środkową. Ta wartość dzieli zbiór danych na dwie równe części.
- Moda: Definiowana jako wartość, która występuje najczęściej w zbiorze danych. Moda jest łatwa do zapamiętania: reprezentuje ona „najpopularniejszą” wartość.

Zalecamy obejrzenie filmu informacyjnego Film o średniej, medianie i modzie na platformie Khan Academy. Ten materiał edukacyjny zawiera jasne i przystępne wyjaśnienia w języku rosyjskim, dzięki czemu nauka statystyki staje się bardziej angażująca i efektywna. Khan Academy pomoże Ci lepiej zrozumieć te ważne koncepcje statystyczne i zastosować je w praktyce.
Oprócz trzech głównych miar, ważne jest rozważenie innych wskaźników statystycznych, w tym miar dyspersji. Jedną z kluczowych miar jest wariancja, która pomaga w głębszej analizie zmienności danych w zbiorze danych. Zrozumienie dyspersji pozwala badaczom i analitykom lepiej interpretować dane, identyfikować wartości odstające i wyciągać trafne wnioski. Analiza wariancji może być również przydatna do oceny stabilności i wiarygodności danych w różnych badaniach i projektach.
2. Zrozumienie dystrybucji danych
Dystrybucja danych jest ważnym aspektem analizy dużych zbiorów danych, umożliwiającym identyfikację zależności między różnymi wielkościami. Tak jak wiek, płeć, a nawet zawód danej osoby można określić na podstawie jej wyglądu, tak rozkład danych pomaga ocenić strukturę i charakterystykę tablic informacyjnych. Zrozumienie rozkładów danych dostarcza analitykom narzędzi do głębszej analizy i interpretacji wyników, co z kolei ułatwia podejmowanie świadomych decyzji w różnych dziedzinach.
Termin „rozkład” pochodzi z teorii prawdopodobieństwa, gdzie każde zdarzenie analizuje się pod kątem prawdopodobieństwa wystąpienia. Nawet jeśli zdarzenia występują z różną częstotliwością, podlegają one określonemu rozkładowi, który porządkuje te prawdopodobieństwa. Rozkłady pozwalają nam badać wzorce w zjawiskach losowych i przewidywać prawdopodobne wyniki w oparciu o dostępne dane. Zrozumienie rozkładów jest kluczowym elementem statystyki i modeli probabilistycznych, co czyni je ważnym narzędziem analizy danych i świadomego podejmowania decyzji.
W kontekście nauki o danych, rozkład reprezentuje prawo zależności między wielkościami. Pomaga zidentyfikować procesy leżące u podstaw danych oraz ocenić ich kompletność i jakość. Zrozumienie rozkładów ma kluczowe znaczenie dla analizy danych i budowania modeli. Jeśli chcesz pogłębić swoją wiedzę na temat matematycznych podstaw nauki o danych, zalecamy zapoznanie się z naszym artykułem „Matematyka dla początkujących”, w którym znajdziesz przydatne informacje i przykłady.
Rozkład normalny, znany również jako rozkład Gaussa, jest jednym z najbardziej znanych typów rozkładów statystycznych. Opisuje on sytuacje, w których wynik końcowy jest sumą wielu niezależnych zmiennych losowych, z których każda ma znikomy wpływ na wynik końcowy. Rozkład normalny odgrywa kluczową rolę w statystyce i obliczeniach prawdopodobieństwa, ponieważ wiele zjawisk naturalnych i społecznych podlega jego prawom. Zrozumienie rozkładu normalnego jest ważne dla analizy danych i stosowania metod statystycznych, ponieważ pozwala wyciągać wnioski na temat dużych próbek w oparciu o ograniczoną ilość informacji.
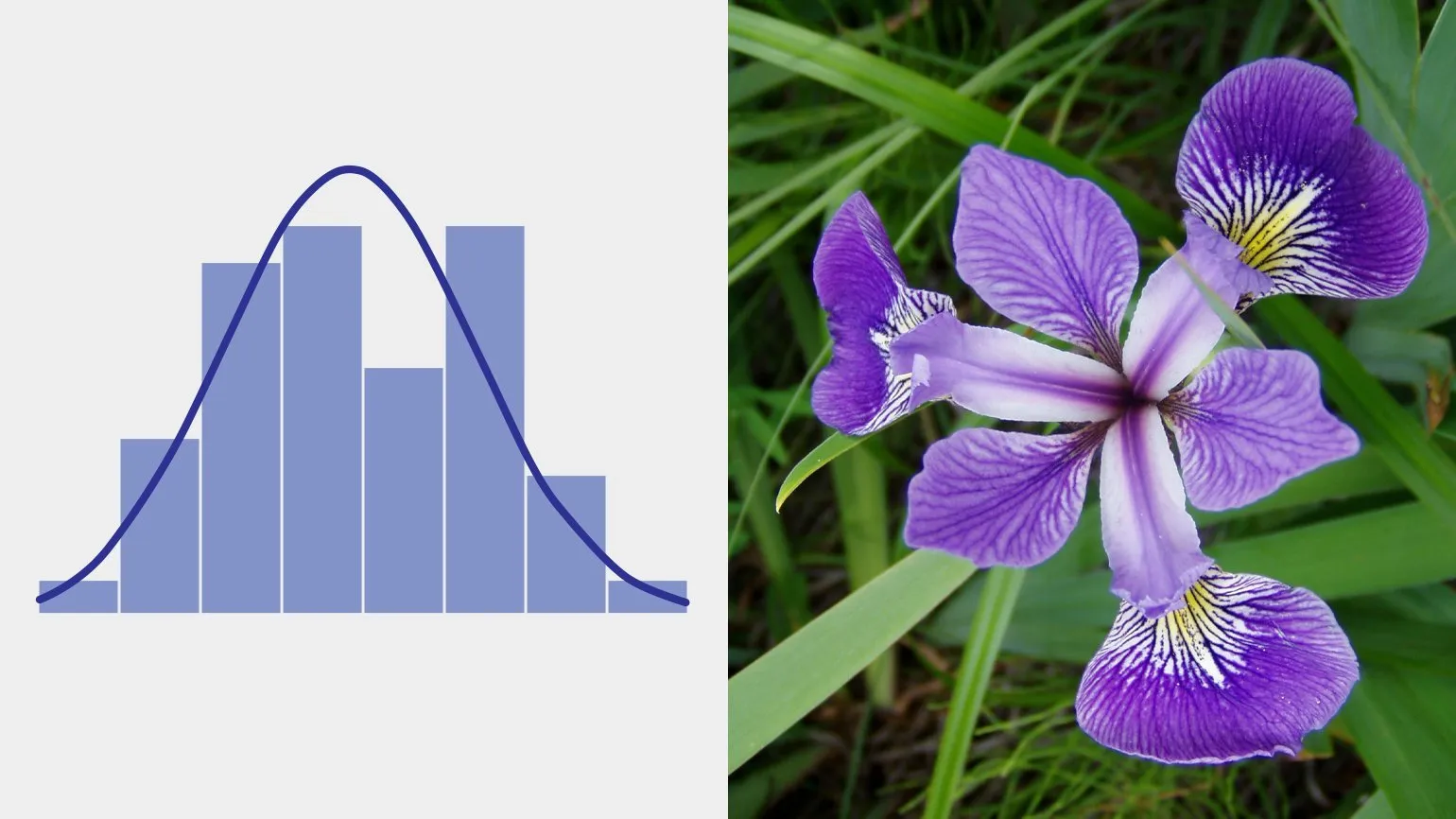
Rozkład normalny jest szeroko stosowany w różnych dziedzinach, od wielkości błędów pomiarowych w fizyce po parametry biologiczne, takie jak długość pazurów i zębów. Rozkład ten jest jednym z najpowszechniejszych w przyrodzie, co potwierdza jego znaczenie i wszechstronność. Rozkład normalny odgrywa kluczową rolę w statystyce i badaniach naukowych, ponieważ wiele zjawisk naturalnych podlega temu regularnemu rozkładowi. Zrozumienie rozkładu normalnego jest ważne dla analizy danych, co czyni go niezbędnym narzędziem w działalności naukowej i praktycznej.
Rozkład Poissona jest jednym z najpowszechniejszych rozkładów statystycznych używanych do modelowania liczby zdarzeń zachodzących w danym przedziale czasu. Rozkład ten jest szczególnie istotny, gdy zdarzenia zachodzą niezależnie od siebie i ze stałą intensywnością. Na przykład rozkład Poissona jest często stosowany w takich dziedzinach jak teoria prawdopodobieństwa, statystyka i różne nauki stosowane, w tym ekonomia i biologia. Pozwala on na skuteczną analizę rzadkich zdarzeń, co czyni go niezbędnym narzędziem dla badaczy i specjalistów.
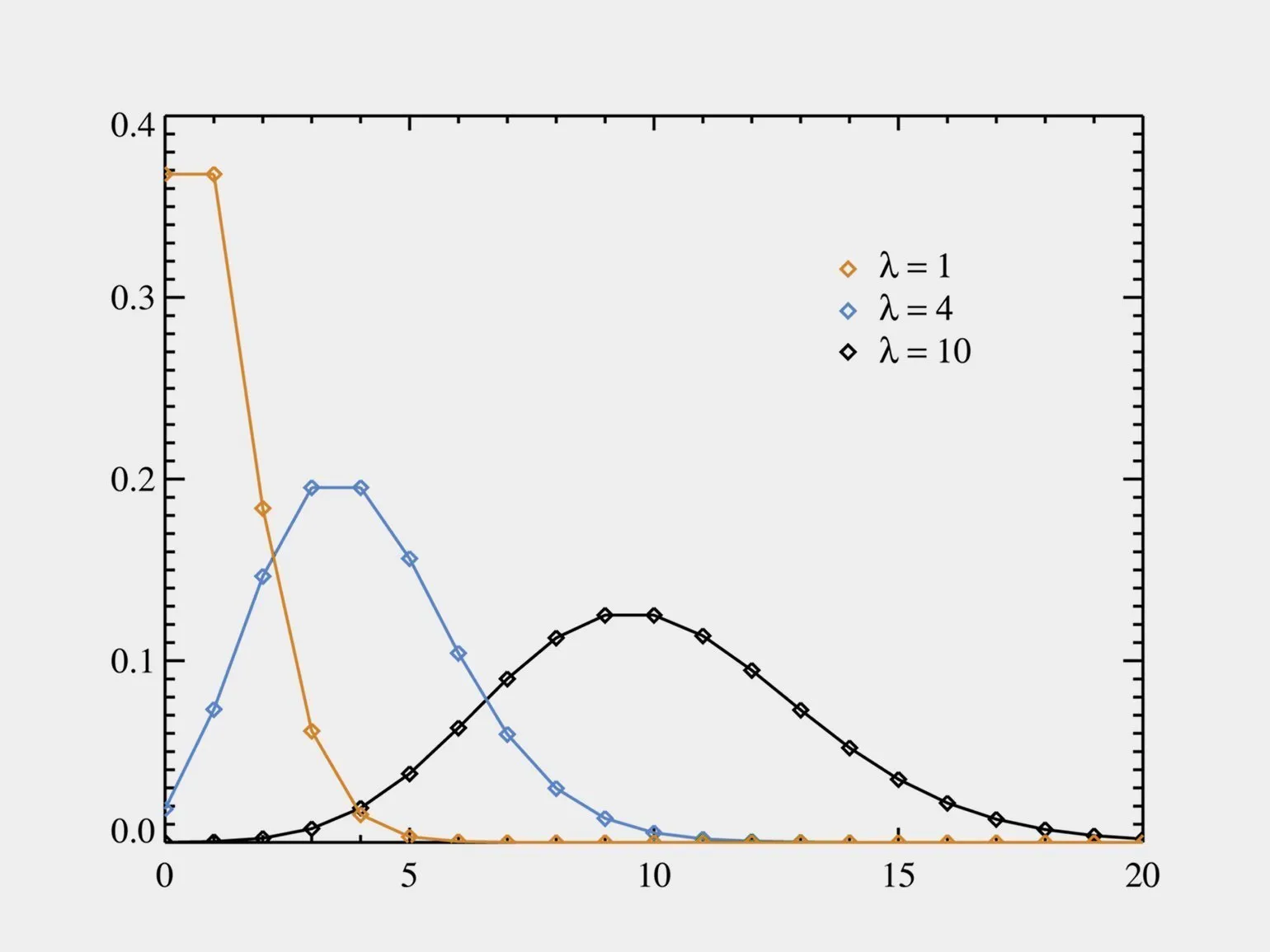
Rozkład Poissona jest szeroko stosowany w różnych dziedzinach, między innymi do liczenia osób w centrach handlowych, analizy wyników sportowych i badania wzrostu kolonii bakteryjnych. Ten model statystyczny pomaga badać rzadkie zdarzenia i przewidywać prawdopodobieństwo ich wystąpienia w danym okresie. Ze względu na swoją wszechstronność rozkład Poissona znajduje zastosowanie w takich dziedzinach jak marketing, medycyna i ekologia, umożliwiając specjalistom efektywne przetwarzanie i analizę danych.
Istnieją również mniej powszechne rozkłady, takie jak rozkład Wignera, Weibulla i Cauchy'ego. Rozkłady te mogą być istotne w specjalistycznych dziedzinach, w tym w fizyce kwantowej. Jednak dla naukowców zajmujących się danymi ważne jest zrozumienie kluczowych rozkładów, ich wykresów i parametrów. Znajomość tych aspektów znacznie usprawnia analizę danych i ułatwia dokładniejszą interpretację wyników. Zrozumienie rozkładów bazowych pomaga w wyborze odpowiednich metod analizy statystycznej i modelowania, co jest niezbędną umiejętnością w nauce o danych.
3. Próbkowanie: Sztuka Wyboru
W dzisiejszym świecie, gdzie dane odgrywają kluczową rolę w podejmowaniu decyzji, zrozumienie próbkowania staje się coraz ważniejsze. Na przykład, aby określić średnią szerokość pyska kotów domowych w naszym kraju, nie można zmierzyć wszystkich zwierząt ze względu na ograniczenia czasowe i zasobowe. W takich przypadkach konieczne jest zastosowanie próbkowania – zmierzenie pysków określonej liczby kotów i wyciągnięcie trafnych wniosków na podstawie tych danych. Prawidłowo przeprowadzone pobieranie próbek pozwala uzyskać dokładne i wiarygodne wyniki, które można wykorzystać do analizy i podejmowania decyzji w różnych dziedzinach.

To podejście rodzi wiele pytań, które wymagają starannej analizy.
- Jaką liczbę i które konkretne koty należy wybrać do pomiaru?
- Dlaczego należy wybrać te konkretne zwierzęta, a nie inne?
- Jakie są gwarancje, że uzyskana średnia wartość rzeczywiście odzwierciedla szerokość pyska wszystkich kotów w Rosji?
Próbkowanie to ważny zestaw metod statystycznych, który umożliwia efektywne badanie cech populacji ogólnej, na przykład wszystkich kotów w danym kraju. Prawidłowo zorganizowane próbkowanie pomaga utworzyć próbę, która najdokładniej odzwierciedla różnorodność i cechy danej populacji. Ma to kluczowe znaczenie dla uzyskania wiarygodnych danych i wniosków, co z kolei przyczynia się do głębszego zrozumienia populacji kotów i ich zachowania.

Prowadząc badania nad kotami, należy pamiętać, że sam pomiar losowo wybranych osobników nie daje obiektywnych wyników. Aby uzyskać wiarygodne dane, niezbędne jest użycie reprezentatywnej próby, która odzwierciedla całą populację. Takie podejście pozwala na wyciągnięcie trafnych wniosków i uzyskanie dokładnych danych analitycznych dotyczących różnych cech kotów. Odpowiednia próba jest kluczem do udanych badań i zapewnienia wiarygodności wyników. Statystyka i koty mają interesującą relację. Wraz z publikacją książki Władimira Sawieliewa o statystyce, wiele osób zaczęło łączyć te dwa tematy. Książka oferuje unikalną perspektywę statystyki z perspektywy kotów, co czyni ją szczególnie atrakcyjną dla wszystkich zainteresowanych tą dziedziną. Zalecamy lekturę prac Sawieliewa, aby lepiej zrozumieć, jak dane statystyczne można powiązać z codziennym życiem, w tym z życiem naszych futrzanych przyjaciół. Metody próbkowania w nauce o danych są kluczowymi narzędziami do tworzenia, przygotowywania i oceny zbiorów danych. Pomagają one zapewnić, że dane są ustrukturyzowane i dokładnie odzwierciedlają rzeczywistość. Prawidłowe próbkowanie pozwala uniknąć stronniczości i zapewnia wysoką jakość analizy, co z kolei prowadzi do dokładniejszych wniosków i prognoz. Skuteczne techniki próbkowania pomagają badaczom i analitykom uzyskać reprezentatywne próby, co jest kluczowe dla analizy dużych wolumenów danych i podejmowania świadomych decyzji.
4. Zrozumienie błędu systematycznego w modelowaniu
Błąd systematyczny w modelu uczenia maszynowego jest kluczowym aspektem, który może znacząco wpłynąć na dokładność prognoz. Występuje, gdy algorytm nieprawidłowo szacuje określone parametry, co może prowadzić do błędnych wniosków. Na przykład, jeśli model turystyczny oferuje wszystkim mieszkańcom Krasnodaru wyłącznie wycieczki do Paryża, ignorując ich indywidualne preferencje i możliwości finansowe, wskazuje to na błąd systematyczny. W takim przypadku model przecenia parametr „Miasto zamieszkania”, co może ostatecznie prowadzić do niezadowolenia użytkowników i obniżenia efektywności usług. Prawidłowe dostrojenie i oszacowanie parametrów modelu są niezbędne do uzyskania dokładniejszych i bardziej spersonalizowanych wyników.
Błąd systematyczny danych może być spowodowany różnymi czynnikami. Do głównych przyczyn należą błędy w gromadzeniu danych, nieprawidłowe przetwarzanie danych, wpływ czynników zewnętrznych oraz zmiany w metodach pomiaru. Należy również uwzględnić czynnik ludzki, który może prowadzić do zniekształcenia danych. Zrozumienie przyczyn stronniczości danych jest kluczowe dla analizy i interpretacji wyników, ponieważ pozwala uniknąć błędnych wniosków i poprawić jakość decyzji.
- Nieprawidłowe gromadzenie danych: w próbie uwzględniono tylko niektóre grupy, na przykład mieszkańców Krasnodaru, którzy kochają Paryż.
- Błędy w tworzeniu zbioru uczącego.
- Niewystarczająca precyzja pomiaru błędu.
Nieprawidłowe gromadzenie danych może powodować systematyczne błędy w doborze informacji. Na przykład w ubiegłym wieku istniał pogląd, że w kosmosie dominują niebieskie galaktyki. Pogląd ten powstał ze względu na specyfikę wrażliwości kliszy fotograficznej na niebieską część widma, która zniekształcała rzeczywistość. Prawidłowe gromadzenie i analiza danych są kluczem do uzyskania dokładnych wniosków naukowych i zrozumienia obiektów kosmicznych.
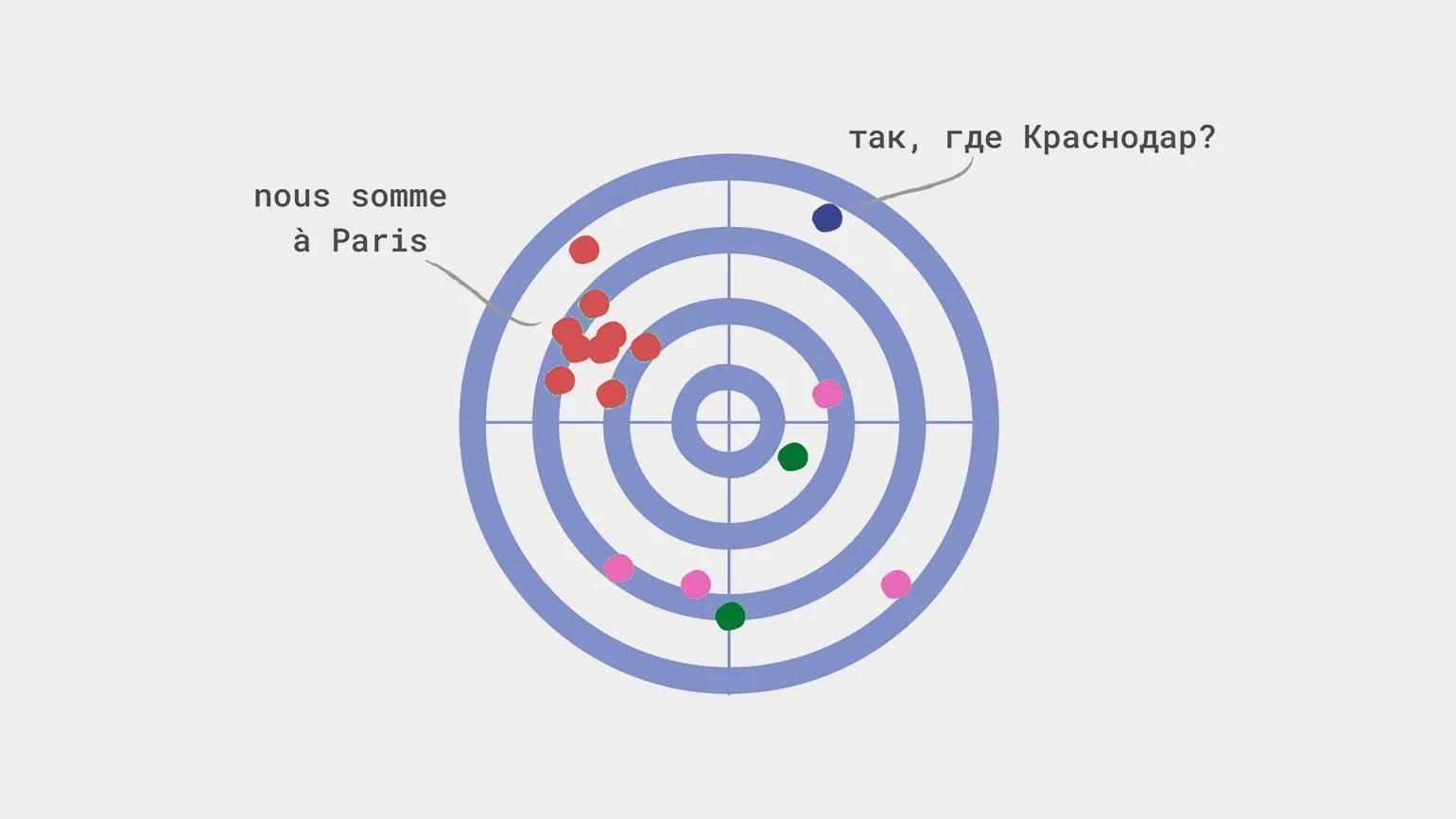
Jeden z powszechnych błędów, zwany „błędem strzelca wyborowego”, występuje, gdy próbka danych jest tworzona wyłącznie na podstawie podobnych wyników. Można to porównać do strzelca, który nakreśla tarczę wokół trafionych punktów, zamiast oceniać rzeczywisty stan rzeczy. Takie podejście zaburza analizę i może prowadzić do błędnych wniosków. Aby uzyskać dokładniejsze i bardziej wiarygodne wyniki, ważne jest uwzględnienie różnorodności danych i unikanie błędów próby.
Przyczyny występowania błędów w danych są tak zróżnicowane, że słynny pisarz Mark Twain zauważył: „Istnieją trzy rodzaje kłamstw: kłamstwa, bezczelne kłamstwa i statystyki”. Kluczowe czynniki przyczyniające się do błędów to selektywne dobieranie próby, stronnicza interpretacja danych oraz zniekształcenia w procesie gromadzenia danych. Aspekty te mogą znacząco wpływać na wnioski i decyzje podejmowane na podstawie danych statystycznych. Zrozumienie przyczyn błędów systematycznych ma kluczowe znaczenie dla poprawy dokładności analizy i zapewnienia wiarygodności wyników.
- Efekt niskiej/wysokiej bazy: jeśli w sprawozdaniach finansowych zgłosisz najniższą marżę zysku, każdy inny wskaźnik będzie wyglądał na udany.
- Skrócenie okresu: aby udowodnić nieskuteczność kampanii reklamowej, wystarczy wybrać okres, w którym pieniądze zostały już wydane, a nie ma żadnych rezultatów.
- Wykluczanie uczestników z próby: jeśli prowadzisz badanie dotyczące utraty wagi, możesz wykluczyć tych, którzy zaprzestali stosowania tej metody, aby poprawić wyniki.
- Klasyczny przypadek: „Badanie wykazało, że 100% populacji korzysta z internetu”.
Błędy błędów systematycznych są trudne do wykrycia za pomocą metod statystycznych, dlatego kluczowe jest zapobieganie im na etapie przygotowań do gromadzenia danych.
Po zebraniu i ustrukturyzowaniu danych ważne jest, aby zadać sobie kilka kluczowych pytań. Po pierwsze, musisz sprawdzić, czy Twoje dane są obarczone błędami systematycznymi. W większości przypadków rzeczywiście może być stronniczy. Drugie pytanie dotyczy kierunku i przyczyny stronniczości. Trzecie pytanie dotyczy tego, czy jest ona dopuszczalna. Analiza tych aspektów pomoże Ci lepiej zrozumieć jakość danych i ich wpływ na wnioski.
Aby lepiej zrozumieć metody ograniczania stronniczości i znaczenie prawidłowego próbkowania danych, ważne jest zapoznanie się z badaniami na renomowanych platformach, takich jak Towards Data Science i KDnuggets. Zasoby te dostarczają cennych materiałów i aktualnych informacji na temat unikania stronniczości danych i poprawy jakości analiz. Korzystanie z tych źródeł pomoże Ci pogłębić wiedzę i umiejętności w zakresie analizy danych i uczenia maszynowego, co jest niezbędne do pomyślnego ukończenia projektów w tej dziedzinie.
Czym jest wariancja i jej znaczenie w statystyce
Wariancja to ważne pojęcie w statystyce i uczeniu maszynowym, które wskazuje stopień rozrzutu wartości w stosunku do ich matematycznego oczekiwania. Pozwala ocenić, w jakim stopniu wyniki modelu lub zwroty finansowe odbiegają od wartości oczekiwanej. Zrozumienie wariancji ma kluczowe znaczenie dla analizy i optymalizacji modeli analitycznych, ponieważ pomaga ocenić ich dokładność i wiarygodność. Zmniejszenie wariancji może wskazywać na zwiększoną stabilność prognoz, co jest szczególnie istotne w kontekście podejmowania decyzji biznesowych i rozwoju efektywnych algorytmów.
Wariancja, jako miara rozrzutu, odgrywa kluczową rolę w analizie zmienności danych. Pozwala ocenić, w jakim stopniu wartości w zbiorze danych odbiegają od średniej. Oczekiwanie matematyczne, które można teoretycznie określić dla różnych rozkładów statystycznych, jest zazwyczaj używane jako wartość bazowa. Najczęściej za ten punkt odniesienia służy prosta średnia arytmetyczna. Zrozumienie wariancji i jej obliczania jest niezbędne do analizy statystycznej, ponieważ pomaga określić stopień zmienności danych i podejmować świadome decyzje w oparciu o wyniki.
Matematyczną wartość oczekiwaną standardowego rzutu kostką można obliczyć w następujący sposób: (1 + 2 + 3 + 4 + 5 + 6) / 6 = 21/6 = 3,5. Wartość ta reprezentuje średni wynik, którego można oczekiwać po dużej liczbie rzutów kostką. Dlatego wartość oczekiwana jest ważnym pojęciem w teorii prawdopodobieństwa i pomaga przewidywać wyniki zdarzeń losowych. Wyobraźmy sobie strzelnicę, na której strzelec stara się trafić w środek tarczy. Strzał w środek daje maksymalnie 10 punktów, a strzał poza środek obniża wynik do 1 punktu na krawędzi tarczy. Każdy strzał można postrzegać jako losową wartość z przedziału od 1 do 10, co wyraźnie ilustruje zasadę wariancji. Ta sytuacja ilustruje, jak czynniki losowe wpływają na wyniki, a także znaczenie precyzji i kontroli w osiągnięciu jak najlepszego wyniku. Zrozumienie wariancji może być przydatne w wielu dziedzinach, od statystyki po podejmowanie decyzji w warunkach niepewności.
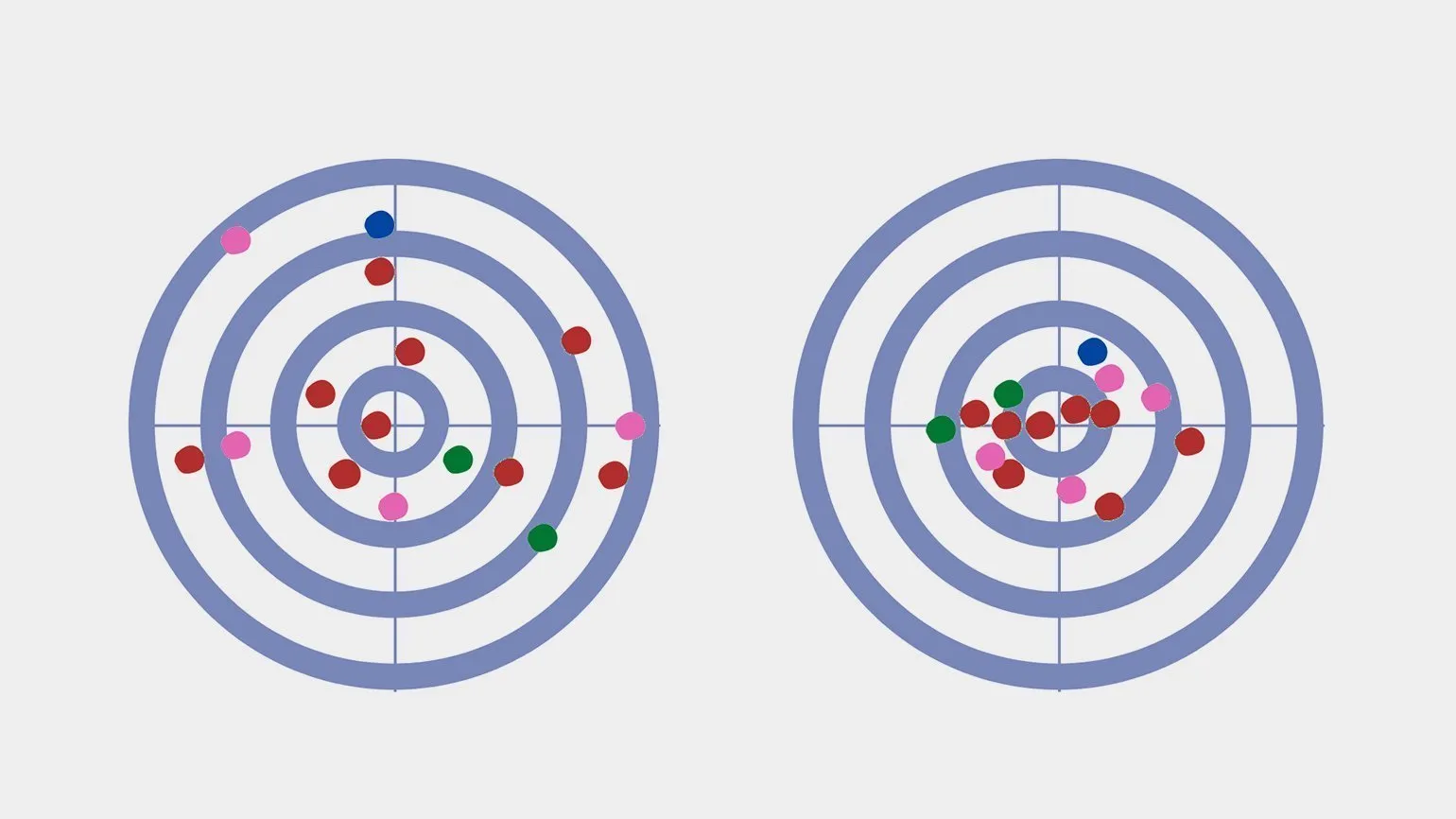
Cel z przeszkodami zapewnia Wizualny przykład rozkładu wyników strzałów. W tym kontekście wariancję można traktować jako odwrotność koncentracji strzałów. Wysoka koncentracja, oznaczająca wiele trafień w to samo miejsce, odpowiada niskiej wariancji. Z kolei niska koncentracja, charakteryzująca rozproszenie trafień, wskazuje na wysoką wariancję. Zrozumienie tej zależności jest ważne dla analizy wyników strzałów i doskonalenia umiejętności.
Zrozumienie wariancji: Jak wpływa ona na analizę danych
Wariancja jest ważnym wskaźnikiem, który nie tylko pomaga ocenić rozrzut danych, ale także stanowi podstawę bardziej zaawansowanych metod statystycznych, takich jak analiza wariancji i konstruowanie przedziałów ufności. Wykorzystanie wariancji w analityce danych umożliwia badaczom i analitykom biznesowym formułowanie dokładniejszych wniosków i prognoz. Zrozumienie wariancji pomaga poprawić jakość analizy i zwiększyć skuteczność podejmowania decyzji opartych na danych.
6. Dylemat błędu systematycznego i wariancji w uczeniu maszynowym
W uczeniu maszynowym błąd systematyczny i wariancja są głównymi czynnikami wpływającymi na ogólny błąd predykcji modelu. Chociaż optymalne wyniki minimalizują zarówno błąd systematyczny, jak i wariancję, pojawia się problem praktyczny: zmniejszenie jednego często zwiększa drugi. Ta sprzeczność wymaga starannego rozważenia podczas opracowywania i dostrajania modeli w celu osiągnięcia jak najlepszych wyników predykcji. Zrozumienie związku między odchyleniem a wariancją może pomóc specjalistom w dziedzinie uczenia maszynowego w optymalizacji modeli i poprawie ich wydajności.

Trenowanie modelu to proces opracowywania funkcji, której wykres dokładnie odzwierciedla dane z zestawu treningowego. Dzięki temu model może skutecznie przewidywać wyniki w oparciu o znane dane. Prawidłowa interpretacja i dostosowanie funkcji do danych treningowych to kluczowe aspekty zapewnienia wysokiej dokładności predykcji.
Jeśli funkcja jest zbyt złożona i przeładowana szczegółami, może to negatywnie wpłynąć na jej zdolność predykcyjną w oparciu o nowe dane, prowadząc ostatecznie do błędu. Zrozumienie tego problemu jest ważne dla tworzenia efektywnych modeli, ponieważ uproszczenie funkcji może poprawić jej zdolność generalizacji i poprawić jakość przewidywań.

Używanie różnych zestawów treningowych lub zbiorów danych może powodować znaczne wahania w prognozach, wskazując na wysoki poziom wariancji. Podkreśla to wagę wyboru wysokiej jakości i reprezentatywnych danych do modeli treningowych w celu zminimalizowania niepewności i poprawy dokładności prognoz. Prawidłowe zaprojektowanie zestawu treningowego prowadzi do bardziej stabilnych i wiarygodnych wyników w uczeniu maszynowym.
Złożone modele zazwyczaj charakteryzują się niskim błędem systematycznym, ale są bardziej podatne na szum i zmienność nowych danych, co może prowadzić do niestabilności ich prognoz. Na przykład, jeśli snajper dostosowuje lunetę w oparciu o nieistotne czynniki, takie jak kolor celu, wpłynie to negatywnie na jego celność w różnych warunkach. Podkreśla to wagę uwzględnienia istotnych zmiennych podczas budowania modeli predykcyjnych, aby zapewnić ich solidność i dokładność w zmieniających się sytuacjach.
Proste modele mogą pomijać kluczowe parametry, co, pomimo możliwości formułowania trafnych prognoz, prowadzi do częstych błędów. Jest to analogiczne do sytuacji snajpera, który nie uwzględnia wiatru ani odległości do celu i w rezultacie go nie trafia. Ważne jest, aby zrozumieć, że w celu osiągnięcia wysokiej dokładności i niezawodności prognozowania konieczne jest uwzględnienie wszystkich istotnych czynników.
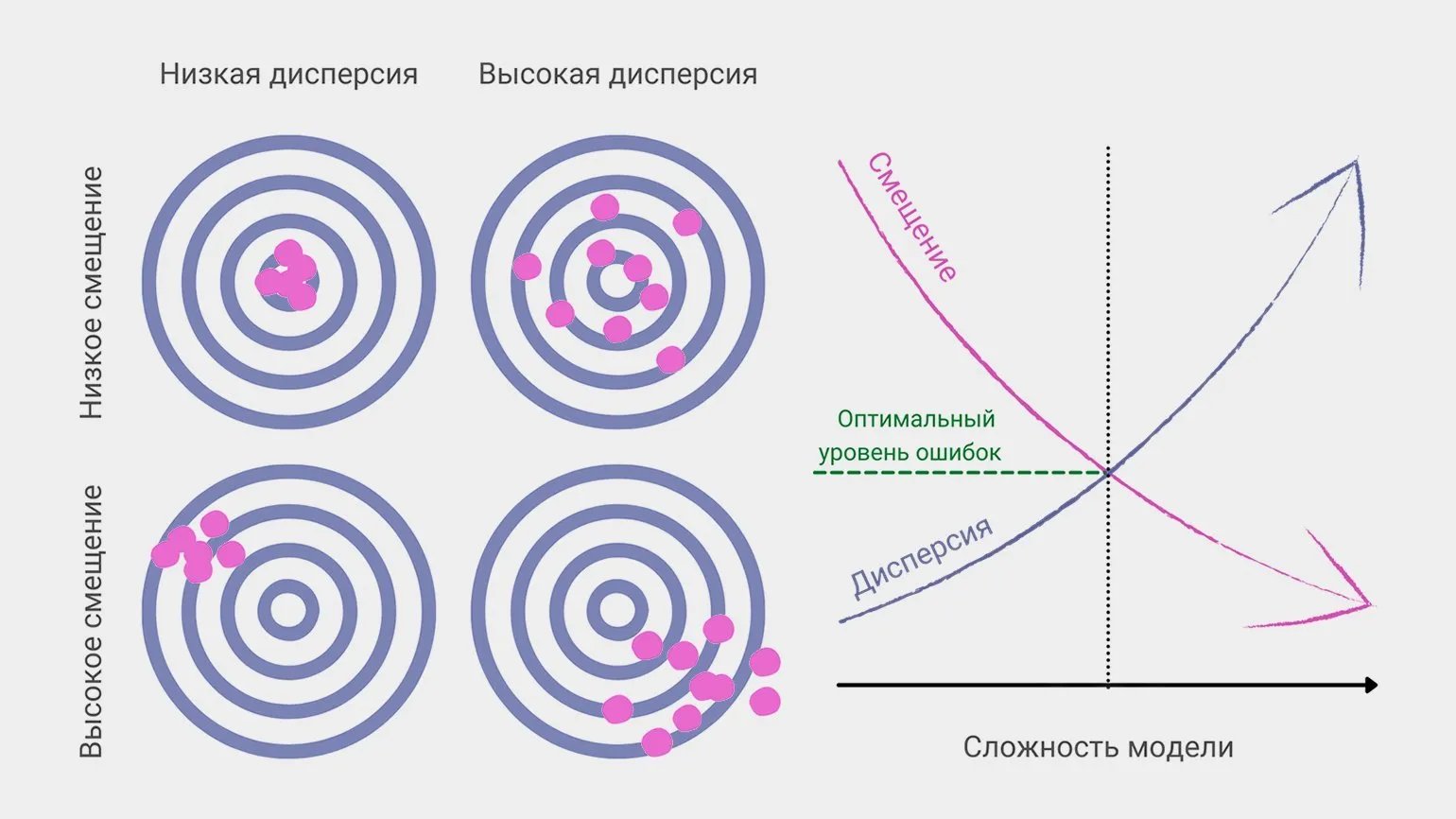
Analityk danych nieustannie dąży do osiągnięcia optymalnej równowagi między błędem a wariancją, aby zminimalizować ogólny błąd prognozy. Wymaga to starannego dostrojenia modelu i dogłębnego zrozumienia charakterystyki danych. Skuteczne zarządzanie błędami i wariancją poprawia jakość prognoz i zwiększa dokładność wnioskowania analitycznego.
Ten dylemat wykracza poza statystykę i uczenie maszynowe. Badanie z 2009 roku wykazało, że ludzie często polegają na heurystyce „wysokie błędy + niska wariancja”: możemy popełniać błędy, ale robimy to z dużym stopniem pewności. To zjawisko ilustruje, jak pewność co do własnych wniosków może być myląca i nie zawsze koreluje z rzeczywistą dokładnością. Zrozumienie takich mechanizmów psychologicznych jest ważne dla usprawnienia analizy danych i podejmowania decyzji, zwłaszcza w obszarach, w których zaufanie do wyników ma kluczowe znaczenie.
Te obserwacje mogą okazać się przydatne dla programistów dążących do stworzenia sztucznej inteligencji zdolnej do podejmowania decyzji bardziej zbliżonych do ludzkich i reagowania na czynniki emocjonalne i społeczne. Zrozumienie tych aspektów pomoże usprawnić interakcję użytkownika ze sztuczną inteligencją i zwiększyć jej skuteczność w różnych dziedzinach.
7. Korelacja: zrozumienie i zastosowanie
Korelacja to zjawisko statystyczne, w którym obserwuje się zależność między zmianami jednej zmiennej a zmianami innej. Warto jednak podkreślić, że występowanie korelacji nie oznacza, że jedna zmienna powoduje zmiany drugiej. Zasada ta jest kluczowa podczas analizy danych i interpretacji wyników. Zrozumienie korelacji i jej różnicy w stosunku do przyczynowości jest ważne dla prawidłowej oceny zależności i podejmowania świadomych decyzji w oparciu o statystyki.
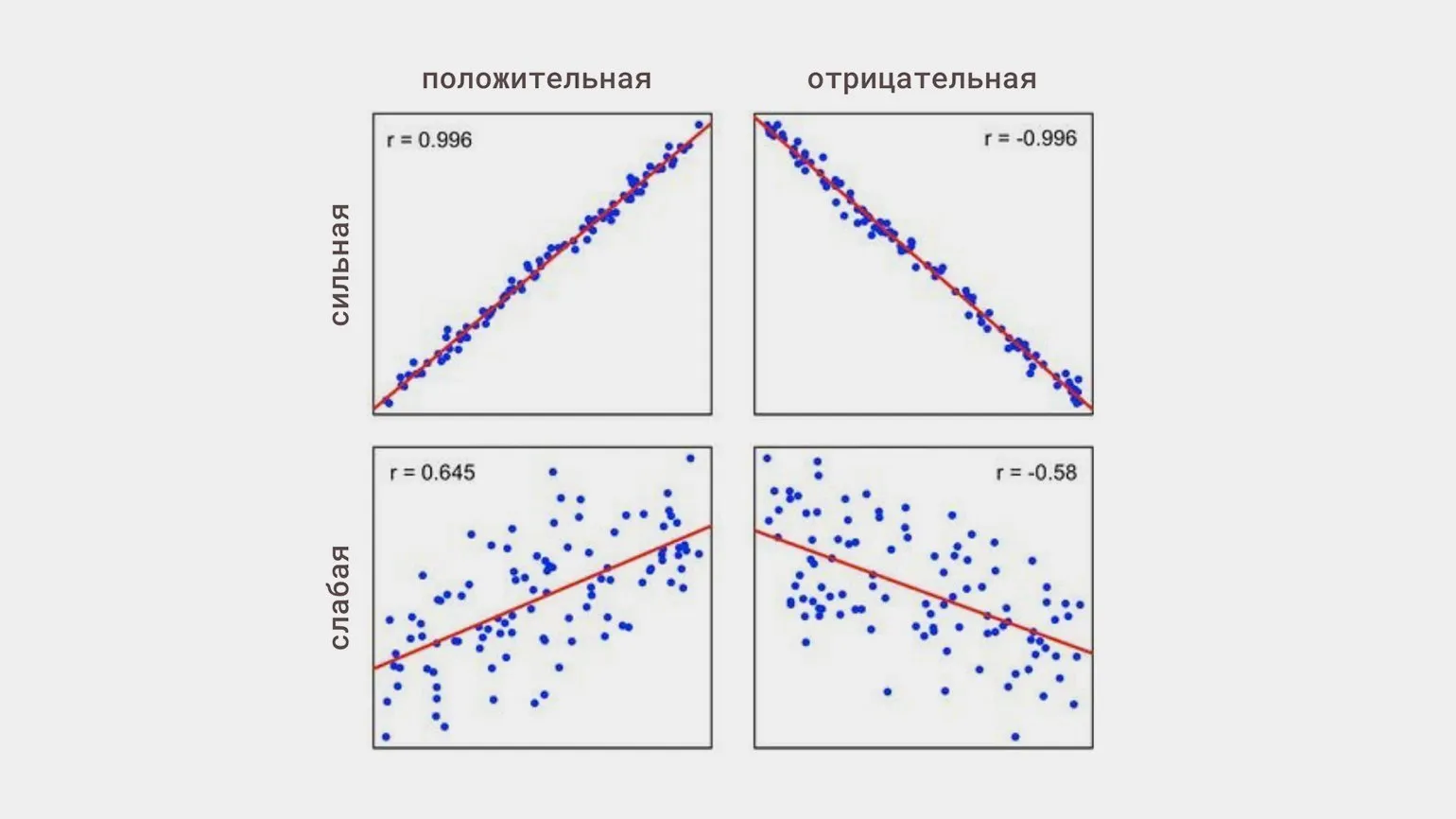
Korelacja liniowa to zależność między dwiema zmiennymi, w której zmiany jednej zmiennej proporcjonalnie wpływają na zmiany drugiej. Korelacja liniowa może być dodatnia, gdy wzrostowi jednej zmiennej towarzyszy wzrost drugiej, lub ujemna, gdy wzrost jednej zmiennej prowadzi do spadku drugiej. Zrozumienie korelacji liniowej jest ważne dla analizy danych, ponieważ pozwala identyfikować i kwantyfikować zależności między zmiennymi. Korelacja liniowa jest wykorzystywana w wielu dziedzinach, takich jak statystyka, ekonomia i nauka, co czyni ją ważnym narzędziem dla badaczy i analityków.
- dodatnia — obie wartości rosną lub maleją jednocześnie;
- ujemna — gdy jedna zmienna rośnie, druga maleje;
- silna lub słaba — niezależnie od kierunku zależności.
Analiza korelacji to metoda służąca do badania zależności statystycznych między zmiennymi. Jej głównym celem jest ocena stopnia zależności między zmiennymi, co pomaga określić, które z nich powinny zostać uwzględnione w modelu, a które nie. Analiza ta może zidentyfikować zarówno korelacje dodatnie, jak i ujemne, co odgrywa ważną rolę w budowaniu efektywnych modeli statystycznych i prognozowaniu. Analiza korelacji jest kluczowym narzędziem w wielu dziedzinach, w tym w ekonomii, socjologii i medycynie, ponieważ pomaga badaczom i analitykom lepiej zrozumieć zależności między różnymi czynnikami.
Należy pamiętać, że korelacja nie zawsze oznacza związek przyczynowo-skutkowy. Nawet jeśli dwa wskaźniki wykazują wysoką korelację, nie oznacza to koniecznie, że są ze sobą powiązane. Konieczna jest bardziej dogłębna analiza, aby ustalić prawdziwe przyczyny zmienności danych i uniknąć fałszywych wniosków.
Projekt „Spurious Correlations” to unikalna platforma, która wizualizuje wykresy korelacji między zupełnie niezwiązanymi ze sobą danymi statystycznymi. Na przykład ilustruje on związek między liczbą utonięć w domowych basenach a liczbą filmów z Nicolasem Cage'em. Takie przykłady podkreślają wagę krytycznego myślenia w analizie danych i ostrzegają przed wyciąganiem bezpodstawnych wniosków na podstawie danych statystycznych. Umiejętność rozróżniania prawdziwych korelacji od zbiegów okoliczności jest niezbędna w badaniach i podejmowaniu decyzji. Projekt podnosi świadomość sztuczek statystycznych i pomaga odbiorcom lepiej zrozumieć, jak interpretować dane we współczesnym świecie.
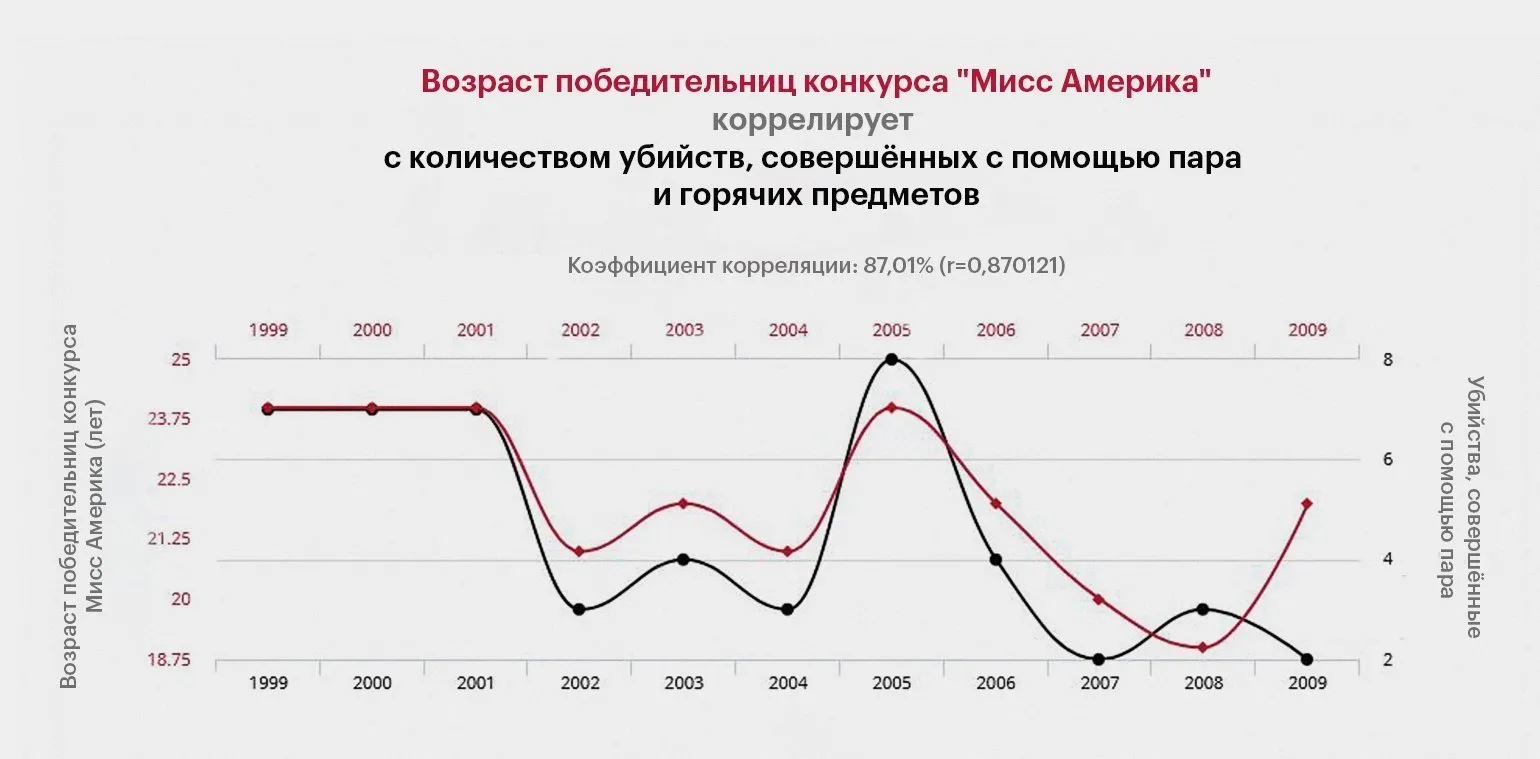
Ciągła analiza danych pomaga zapobiegać zespołowi głębokiej korelacji (DCS) i pogłębia zrozumienie zależności statystycznych. Regularne korzystanie z informacji statystycznych pomaga identyfikować rzeczywiste trendy i unikać fałszywych wniosków, co jest szczególnie ważne dla badaczy i analityków. Pomaga to podejmować bardziej świadome decyzje w oparciu o faktyczne dane, a nie spekulacje.
Programista Python: 3 projekty na udany start
Chcesz zostać programistą Python? Dowiedz się, jak stworzyć 3 projekty portfolio i uzyskaj pomoc w poszukiwaniu pracy!
Dowiedz się więcej